通过不断解决一些场景问题,循序渐进地介绍Docker网络。
我们知道Docker的网络是一个与宿主机隔离的网络(不使用--host),让我们进入第一个问题:如何创建隔离的容器网络
Q1 创建隔离的容器网络 #
我们引入第一个概念 namespace。
在 Linux 中,namespace(命名空间)是一个用来隔离资源视图的机制。它为不同的进程分配不同的“视野”,使得进程自己“看起来”拥有了独立的资源。有很多种 namespace,在网络资源层面是 network namespace,进程拥有隔离的网络栈(包括IP、路由表等),不同的 network namespace 之间的网络配置互不干扰。
在宿主机上可以使用 ip netns 命令来进行 network namespace 管理:
# 创建netns
ip netns add mynetns0
ip netns list
mynetns0
# 在 mynetns0 netns 中执行命令
ip netns exec mynetns0 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
注意本地回环接口状态默认是DOWN的,我们可以将接口UP,并分别在2个终端中做如下测试:
终端A
ip netns exec mynetns0 ip link set lo up
ip netns exec mynetns0 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
# 在 mynetns0 netns 下运行 http 服务
ip netns exec mynetns0 python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
终端B
# 在 host netns 下访问失败
curl localhost:8000
curl: (7) Failed to connect to localhost port 8000 after 0 ms: Could not connect to server
# 在 mynetns0 netns 访问成功
ip netns exec mynetns0 curl localhost:8000
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Directory listing for /</title>
</head>
<body>
<h1>Directory listing for /</h1>
</body>
</html>
当你运行docker run启动容器时,Docker daemon会在内核中为容器创建新的network namespace,并对该namespace进行网络配置(例如分配 IP、路由等)。文章后续,我们就用新创建的ns表示一个容器(的网络环境)。
此时的网络拓扑如下: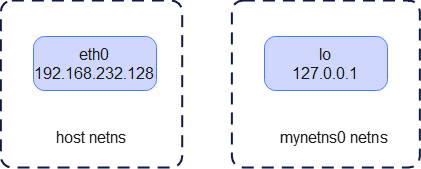
成功创建了隔离的容器网络环境,又有了一个新问题:我们一边希望他是与宿主机隔离的网络环境,这样可以不弄乱宿主机的网络环境;同时也希望能在宿主机和容器网络环境之间互相访问
Q2 宿主机和容器网络互访 #
我们引入第二个概念 veth(Virtual Ethernet)。
veth 是一种虚拟网络设备,通常成对出现(veth pair)。两个端口之间像一根虚拟网线,数据“从一端进”后,就会“从另一端出”。
如果把 veth pair 的一个接口放到容器的 network namespace 中,另一个接口留在宿主机上或者放到另外一个 network namespace 中,那么这两个 namespace 之间就能通过这条 veth 通路来通信。
通过以下命令实现:
- 创建一对
veth:veth_abc/veth_ns_abc - 将
veth_ns_abc移动到mynetns0ns 中,veth_abc则继续在hostns中 - 分配
10.0.0.10IP给veth_abc,10.0.0.11IP给veth_ns_abc
# 创建一对veth
ip link add dev veth_abc type veth peer name veth_ns_abc
ip addr
3: veth_ns_abc@veth_abc: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 82:aa:4f:54:3e:65 brd ff:ff:ff:ff:ff:ff
4: veth_abc@veth_ns_abc: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:5e:20:df:d7:5e brd ff:ff:ff:ff:ff:ff
# 移动ns
ip link set dev veth_abc up
ip link set veth_ns_abc netns mynetns0
ip netns exec mynetns0 ip addr
3: veth_ns_abc@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 82:aa:4f:54:3e:65 brd ff:ff:ff:ff:ff:ff link-netnsid 0
ip netns exec mynetns0 ip link set dev veth_ns_abc up
# 分配IP
ip address add 10.0.0.10/24 dev veth_abc
ip netns exec mynetns0 ip address add 10.0.0.11/24 dev veth_ns_abc
宿主机访问容器
ping -c 4 10.0.0.11
PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data.
64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=0.024 ms
64 bytes from 10.0.0.11: icmp_seq=2 ttl=64 time=0.029 ms
64 bytes from 10.0.0.11: icmp_seq=3 ttl=64 time=0.024 ms
64 bytes from 10.0.0.11: icmp_seq=4 ttl=64 time=0.027 ms
--- 10.0.0.11 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3050ms
rtt min/avg/max/mdev = 0.024/0.026/0.029/0.002 ms
容器访问宿主机
ip netns exec mynetns0 ping -c 4 10.0.0.10
PING 10.0.0.10 (10.0.0.10) 56(84) bytes of data.
64 bytes from 10.0.0.10: icmp_seq=1 ttl=64 time=0.026 ms
64 bytes from 10.0.0.10: icmp_seq=2 ttl=64 time=0.032 ms
64 bytes from 10.0.0.10: icmp_seq=3 ttl=64 time=0.027 ms
64 bytes from 10.0.0.10: icmp_seq=4 ttl=64 time=0.029 ms
--- 10.0.0.10 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3067ms
rtt min/avg/max/mdev = 0.026/0.028/0.032/0.002 ms
访问宿主机的其他网卡,如eth0: 192.168.232.128,需要将10.0.0.10设为网关
ip addr
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:50:56:2b:0e:22 brd ff:ff:ff:ff:ff:ff
inet 192.168.232.128/24 brd 192.168.232.255 scope global dynamic noprefixroute eth0
ip netns exec mynetns0 ping -t 4 192.168.232.128
ping: connect: Network is unreachable
ip netns exec mynetns0 ip route
10.0.0.0/24 dev veth_ns_abc proto kernel scope link src 10.0.0.11
# 添加路由,10.0.0.10作为网关
ip netns exec mynetns0 ip route add default via 10.0.0.10
ip netns exec mynetns0 ping -c 4 192.168.232.128
PING 192.168.232.128 (192.168.232.128) 56(84) bytes of data.
64 bytes from 192.168.232.128: icmp_seq=1 ttl=64 time=0.025 ms
64 bytes from 192.168.232.128: icmp_seq=2 ttl=64 time=0.025 ms
64 bytes from 192.168.232.128: icmp_seq=3 ttl=64 time=0.029 ms
64 bytes from 192.168.232.128: icmp_seq=4 ttl=64 time=0.055 ms
--- 192.168.232.128 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3053ms
rtt min/avg/max/mdev = 0.025/0.033/0.055/0.012 ms
此时的网络拓扑如下:
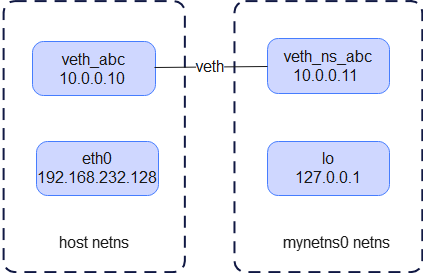
宿主机和容器网络能成功互访了,又有了一个新问题:我们一般会运行多个容器,比如一个web容器需要访问另外一个db容器,如何让多个容器之间互访
Q3 多个容器互访 #
多个容器互访显然可以继续使用上面veth的方案,每对需要互访的容器增加一对veth,但是随着互访数量增加显然不易于管理。
我们引入第三个概念 bridge(网桥)。
bridge 是 Linux 提供的一个二层转发设备,类似于网络交换机。所有添加到同一个 bridge 的网络接口之间处于同一个二层广播域,它会根据 MAC 地址进行帧转发。bridge 同时也被当作内核中的一类“网络接口”来对待,既具备了二层转发的功能,又可以作为一个“虚拟网卡”出现在系统网络栈中,所以就能够像给其它网卡一样给它配置 IP。
假设有多个容器网路环境,我们将所有veth对留在hostns的一端接入到网桥中,那么这多个容器即可以实现互访。
添加另外一个ns mynetns1,模拟另一个容器网络环境
ip netns add mynetns1
ip netns list
mynetns0
mynetns1
# 创建一对veth
ip link add dev veth_def type veth peer name veth_ns_def
# 移动ns
ip link set dev veth_def up
ip link set veth_ns_def netns mynetns1
ip netns exec mynetns1 ip link set dev veth_ns_def up
# 分配IP
ip netns exec mynetns1 ip address add 10.0.0.21/24 dev veth_ns_def
创建bridge0,并让veth_abc和veth_def接入bridge0,同时注意这2张网卡也不再需要IP
# 删除veth_abc原有分配的IP
ip address del 10.0.0.10/24 dev veth_abc
# 创建bridge
ip link add dev bridge0 type bridge
ip link set bridge0 up
# 接入master
ip link set dev veth_abc master bridge0
ip link set dev veth_def master bridge0
互访验证通过:
ip netns exec mynetns0 ping -c 4 10.0.0.21
PING 10.0.0.21 (10.0.0.21) 56(84) bytes of data.
64 bytes from 10.0.0.21: icmp_seq=1 ttl=64 time=0.096 ms
64 bytes from 10.0.0.21: icmp_seq=2 ttl=64 time=0.039 ms
64 bytes from 10.0.0.21: icmp_seq=3 ttl=64 time=0.052 ms
64 bytes from 10.0.0.21: icmp_seq=4 ttl=64 time=0.036 ms
--- 10.0.0.21 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3054ms
rtt min/avg/max/mdev = 0.036/0.055/0.096/0.024 ms
ip netns exec mynetns1 ping -c 4 10.0.0.11
PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data.
64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=0.050 ms
64 bytes from 10.0.0.11: icmp_seq=2 ttl=64 time=0.035 ms
64 bytes from 10.0.0.11: icmp_seq=3 ttl=64 time=0.039 ms
64 bytes from 10.0.0.11: icmp_seq=4 ttl=64 time=0.040 ms
--- 10.0.0.11 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3053ms
rtt min/avg/max/mdev = 0.035/0.041/0.050/0.005 ms
同时为了保证Q2 宿主机和容器网络互访需求,可以为bridge0设置IP地址为10.0.0.1/24,并将mynetns0和mynetns1中的网关指向它
ip address add 10.0.0.1/24 dev bridge0
# 删除mynetns0中的原有路由
ip netns exec mynetns0 ip route delete default via 10.0.0.10
ip netns exec mynetns0 ip route add default via 10.0.0.1
ip netns exec mynetns1 ip route add default via 10.0.0.1
# 宿主机和容器网络互访验证
## 容器->宿主机
ip netns exec mynetns0 ping -c 1 192.168.232.128
PING 192.168.232.128 (192.168.232.128) 56(84) bytes of data.
64 bytes from 192.168.232.128: icmp_seq=1 ttl=64 time=0.036 ms
--- 192.168.232.128 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.036/0.036/0.036/0.000 ms
ip netns exec mynetns1 ping -c 1 192.168.232.128
PING 192.168.232.128 (192.168.232.128) 56(84) bytes of data.
64 bytes from 192.168.232.128: icmp_seq=1 ttl=64 time=0.053 ms
--- 192.168.232.128 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.053/0.053/0.053/0.000 ms
## 宿主机->容器
ping -c 1 10.0.0.11
PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data.
64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=0.042 ms
--- 10.0.0.11 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.042/0.042/0.042/0.000 ms
ping -c 1 10.0.0.21
PING 10.0.0.21 (10.0.0.21) 56(84) bytes of data.
64 bytes from 10.0.0.21: icmp_seq=1 ttl=64 time=0.041 ms
--- 10.0.0.21 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.041/0.041/0.041/0.000 ms
此时的网络拓扑如下:
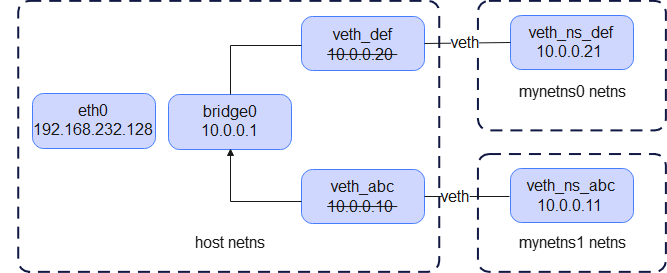
Docker 在宿主机上默认创建了一个名为docker0的网桥设备。Docker 创建veth pair中的一端放入容器,另一端绑定到docker0网桥上。Docker 从内部的地址池(默认172.17.0.0/16)中为容器分配一个 IP 地址,并配置在容器的eth0上。docker0网桥本身也会有一个对应的 IP(默认172.17.0.1),充当网关,容器通过这个网关访问外部网络。
我们在保证宿主机和容器能互访的情况下,成功实现了多个容器互访,目前都局限于宿主机环境内部。又有了一个新问题:容器可能会需要进行apt install xxx操作需要访问互联网等外部网络,容器内部如何与外部互访
Q4 容器内部与外部互访 #
我们引入第四个概念 iptables。
当要实现容器访问外部网络时,可以在 iptables -t nat 表中添加源地址转换 SNAT(MASQUERADE)规则。当容器流量从 bridge0 网桥流出,经过这条 NAT 规则后,源 IP 会被改写为宿主机网络接口对应的 IP,这样外部网络会把响应包返回到宿主机 IP。Linux 内核通过连接跟踪(conntrack)记录了出站时 NAT 改写的映射关系。当外部回复包返回到宿主机时,iptables 会根据 conntrack 表中的记录,将目标 IP 从宿主机 IP 还原为之前被改写的容器 IP,再把包转发回容器。
操作如下:
# 开启数据包转发,将从一个网络接口(例如 bridge0)进来的包再转发到另一个网络接口(例如 eth0)
echo 1 > /proc/sys/net/ipv4/ip_forward
# 通过iptables将 IP来源为 10.0.0.0/24 且输出接口不是 bridge0 (即流量要出去)的流量 SNAT出去
iptables -t nat -A POSTROUTING -s 10.0.0.0/24 ! -o bridge0 -j MASQUERADE
ip netns exec mynetns1 ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=37.6 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 37.612/37.612/37.612/0.000 ms
当要实现外部网络访问容器时,类似docker run -p 18000:8000,可以在 iptables -t nat 表中添加目的地址转换 DNAT 规则。实现容器端口映射到宿主机,外部网络访问宿主机端口的流量会被“转发”给容器对应端口。
操作如下:
iptables -t nat -A PREROUTING -p tcp --dport 18000 -j DNAT --to-destination 10.0.0.11:8000
# 本机“发给本机”的流量也走 DNAT
# 源 IP 和目标 IP 如果都是本机(尤其当目标 IP 就是本机网卡 IP,比如 192.168.232.128)时,
# 那么数据包默认不会经过 PREROUTING 链和 FORWARD 链,而只会走本机的 OUTPUT -> INPUT 路径
iptables -t nat -A OUTPUT -p tcp -d 192.168.232.128 --dport 18000 -j DNAT --to-destination 10.0.0.11:8000
# 由于经过 DNAT 的包还要从宿主机“转发”到容器,需添加 FORWARD 链允许
iptables -A FORWARD -p tcp -d 10.0.0.11 --dport 8000 -j ACCEPT
curl 192.168.232.128:18000
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Directory listing for /</title>
</head>
<body>
<h1>Directory listing for /</h1>
<hr>
<hr>
</body>
</html>
实际上 Docker 管理的iptables规则会更复杂,会配置许多子链等。这里只是简单演示说明。
Q5 跨节点容器互访 #
Docker 自身并不提供跨节点容器互访的能力(除了被淘汰的docker swarm),需要 Overlay / BGP 等技术实现,TODO