1 K8s基本 #
1.1 kubectl #
kubectl 是 K8s 的官方命令行工具,通过Restful API的方式与 Kubernetes API 交互,管理和操作 K8s 集群。
使用参数如下,为 动词 + 资源类型 + 资源名称 + 参数


当然还有其他客户端,python,go相关的client工具都有,用于在不同的语言代码中集成对K8s集群的访问能力,本质都是向API Server发送Restful API请求
1.2 API Resources #
我们可以使用以下命令查看集群当前支持的API资源
kubectl api-resources
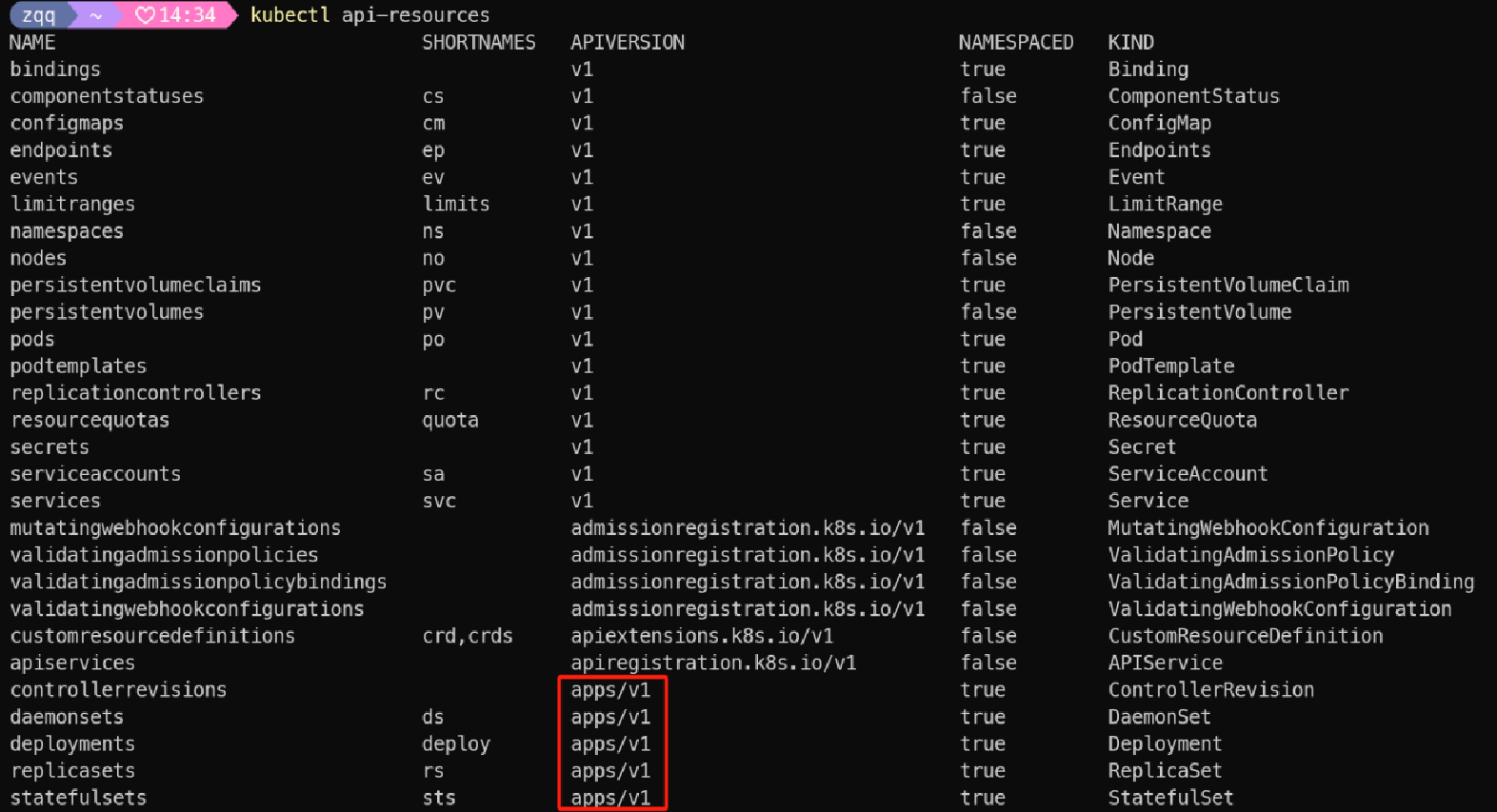
日常工作经常接触的类型,deploy/configmap/service等,还可以看到有些资源是NAMESPACED,即有命名空间概念的
kubeconfig 文件告诉
kubectl如何连接和认证到 Kubernetes 集群。kubectl查找 kubeconfig 文件的顺序遵循如下优先级(从高到低):
- 在命令行中通过
--kubeconfig选项指定路径时,只会使用该文件- 如果没有在命令行显式指定,会检查环境变量
KUBECONFIG- 如果上述两种都没有设置,则使用默认路径
~/.kube/config
1.3 Node #
Node 是运行Pod的机器,可以是物理机或者虚拟机

我们对node常见的操作有升级一个节点,则进行不可调度和驱逐

关于以上命令的解释,drain = cordon + evict,cordon:将节点标记为不可调度,evict:驱逐节点上可驱逐的 Pod。
默认情况下,DaemonSet 管理的 Pod 不会被驱逐,且 为了防止误操作 drain 遇到这些 Pod 会报错并终止。加上
--ignore-daemonsets参数后,drain 会 跳过 DaemonSet Pod,不再报错,继续驱逐其他 Pod,等价于用户已确认这些 Pod 可安全忽略。
我们也可以通过以下yaml虚假的创建一个节点,但是这是没有意义的,创建的节点也不会变为Ready状态。因为node节点是自注册的,每个节点上的 kubelet 会向控制平面 自注册,K8s 内部创建一个对应的 Node 对象,如果该节点未变为Ready健康状态,则 K8s 忽略该节点的集群活动。
apiVersion: v1
kind: Node
metadata:
name: minikube2
labels:
node-role.kubernetes.io/worker: ""
spec:
taints:
- key: "example.com/custom"
value: "true"
effect: "NoSchedule
1.4 Pod #
Pod 是最小、最简单的 K8s 对象,代表一组正在运行的容器。
Pod 中的多个容器共享同一个网络命名空间(IP、端口)和存储卷,这使得它们可以协同工作。
Pod直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚。

但在英语中,会将 a group of whales(一群鲸鱼)称作 a pod of whales,Pod就是来源于此,(出处《Kubernetes修炼手册》),个人认为也更加符合上面说的航海生态。

Pod 很少会在业务中直接使用他,基本都是通过创建后面介绍的工作负载间接涉及。Pod的设计理念是短生命周期(ephemeral in nature)的,即你不能依赖或者要求pod能稳定运行,同时Pod IP 与 Pod 生命周期绑定,不具备稳定性。Pod UID 变了,IP 就变了。节点资源紧张(如内存不足),Kubelet 会驱逐 Pod。驱逐后的 Pod 会被调度到新节点重新创建,因此 IP 会变。
以下yaml创建了一个pod,展示了一个 多容器协作的日志共享示例,核心点是一个写日志到文件,一个从文件渡日治,并使用 emptyDir 卷 实现容器间文件共享。
apiVersion: v1
kind: Pod
metadata:
name: http-log-demo
labels:
app: my-app
spec:
volumes:
- name: shared-logs
emptyDir: {}
containers:
- name: web
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "while true; do { echo -e 'HTTP/1.1 200 OK\r\n'; echo \"$(date) Request from $RANDOM\" >> /logs/access.log; } | nc -l -p 8080; done"]
ports:
- containerPort: 8080
volumeMounts:
- name: shared-logs
mountPath: /logs
- name: log-reader
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "tail -f /logs/access.log"]
volumeMounts:
- name: shared-logs
mountPath: /logs
# 创建以上yaml对应的pod
kubectl apply -f pod.yaml
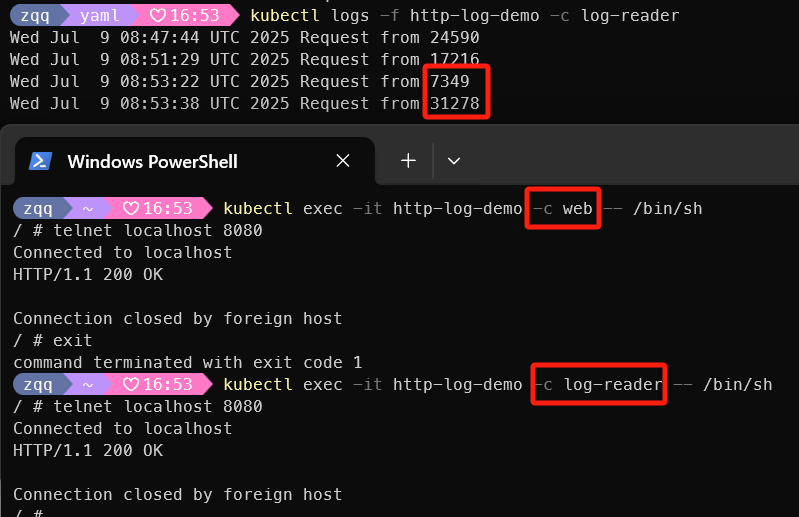
# 通过进入不同的容器,发现多个容器共享一个网络命名空间和存储卷
kubectl exec -it http-log-demo -c web -- /bin/sh
telnet localhost 8080
exit
kubectl exec -it http-log-demo -c log-reader -- /bin/sh
telnet localhost 8080
exit
# 查看日志 -c 指定容器
kubectl logs -f http-log-demo -c log-reader
1.5 Namespace #
命名空间是一抽象对象,提供了一种隔离单个集群内资源组的机制。
Nodes, PersistentVolumes 是没有命名空间概念的,Deployments,Services 则有。对于命名空间对象,不指定命名空间,则默认是指 default 命名空间,该命名空间是K8s自动初始化好的。
1.6 Service #
服务提供了一种方法,能够以稳定的IP或域名方式,访问一组Pods。解决 Pod IP 不稳定带来的问题,并实现负载均衡等功能。
Service主要有以下3种类型,ClusterIP/NodePort/LoadBalancer:
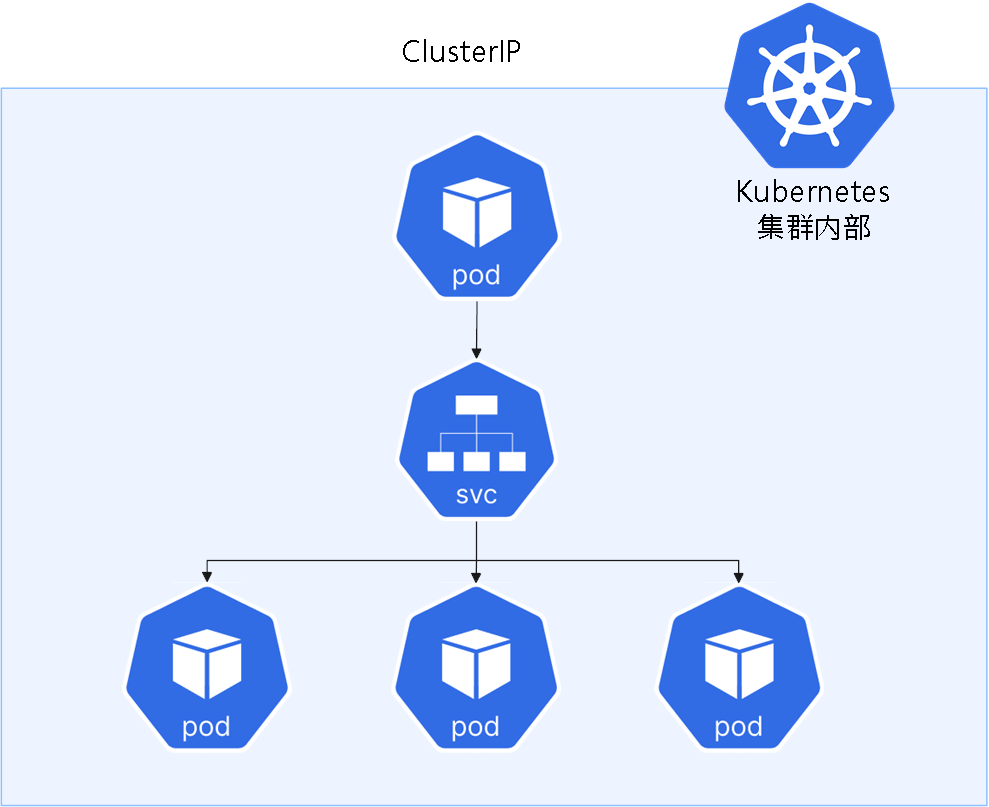
ClusterIP(默认类型): 在集群内部创建一个虚拟 IP(ClusterIP),供集群内的其他 Pod 访问。适用于集群内服务间通信,不能被集群外部直接访问。
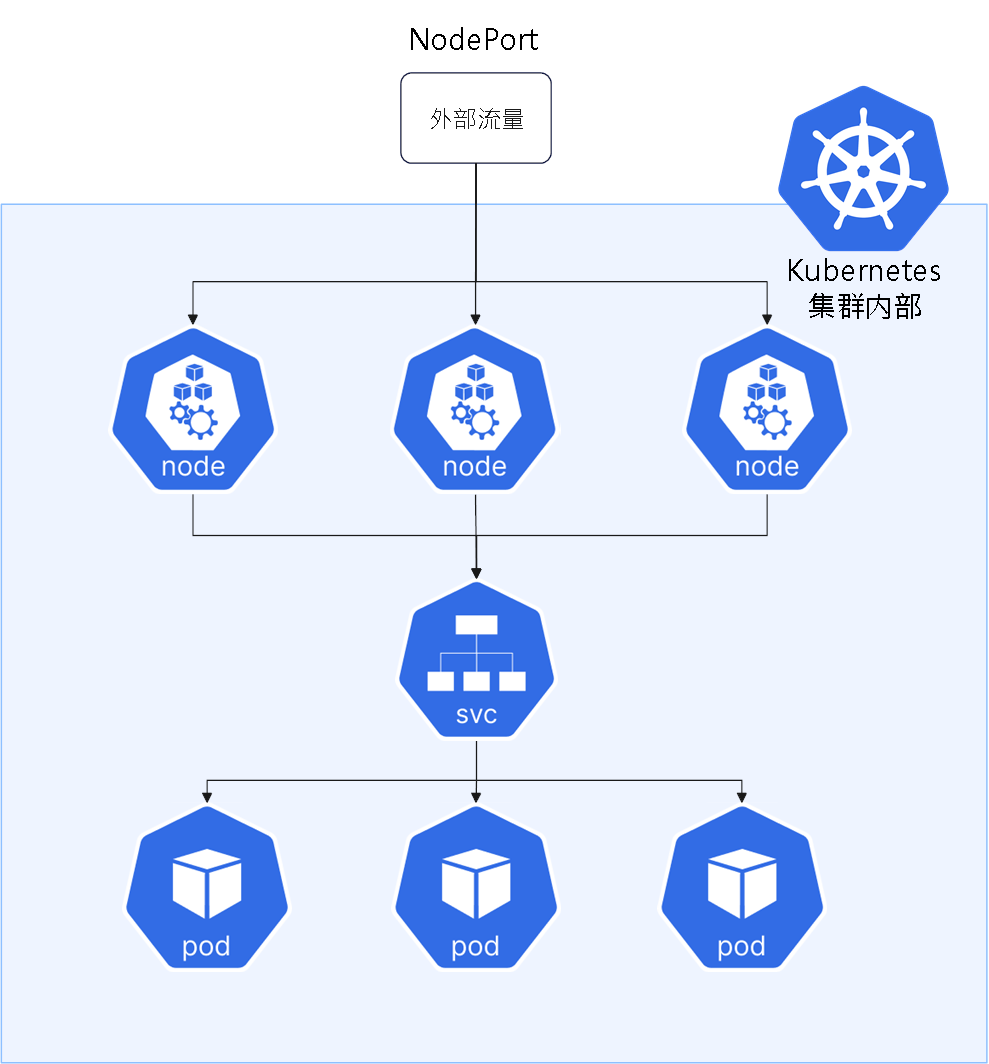
NodePort:在所有节点上开放一个固定端口(30000–32767),把访问转发到对应的 Pod。允许从集群外通过<NodeIP>:<NodePort>访问服务。
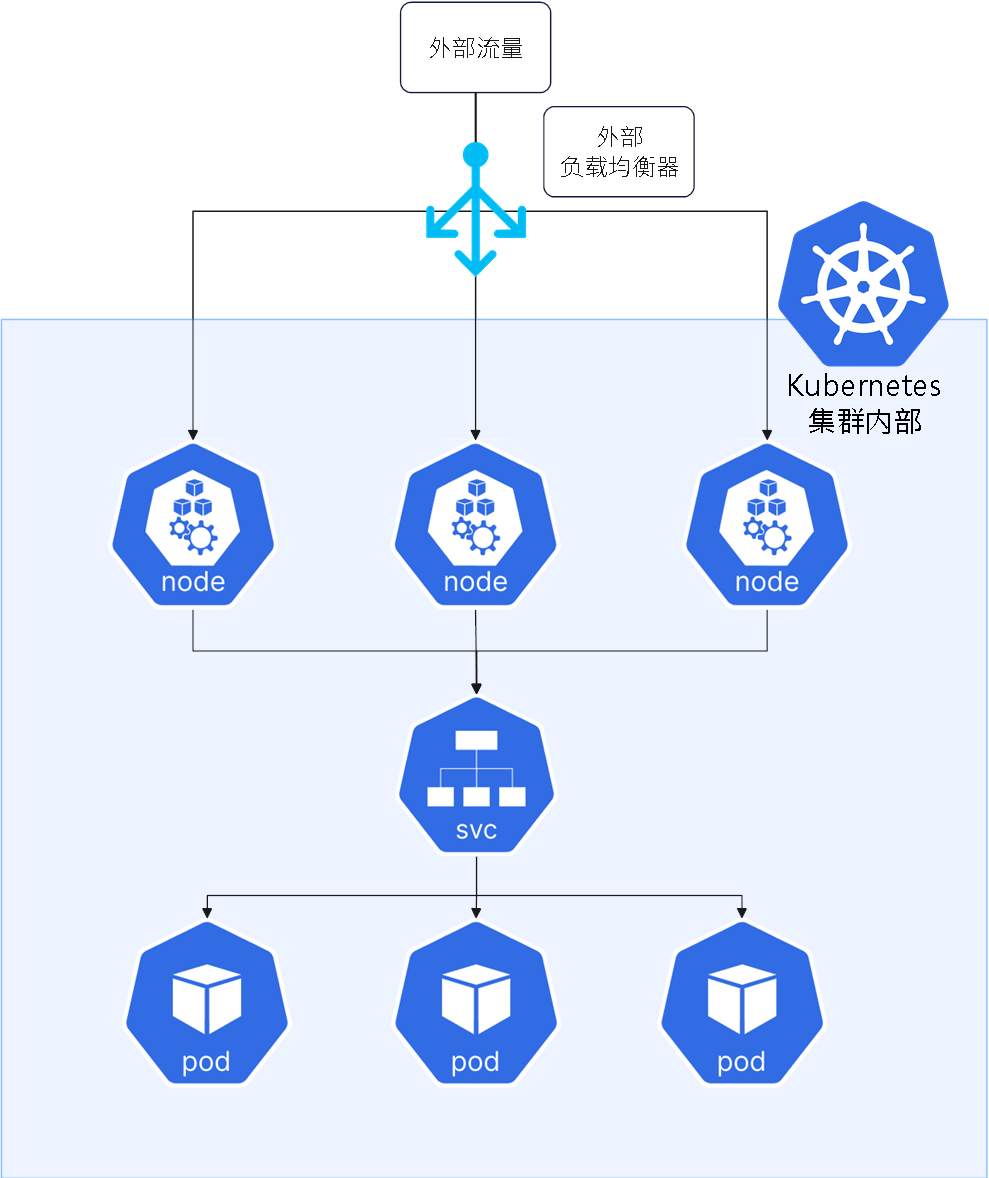
LoadBalancer:在外部如公有云(如 AWS、GCP、Azure)上自动创建一个外部负载均衡器,分发流量到节点,再转发给 Pod。适合生产环境对外暴露服务,依赖集群外部提供的负载均衡能力。
3种服务之间拥有如下关系,是为超集的关系:
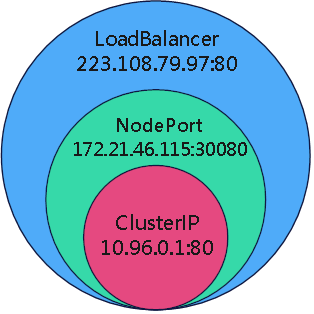
倒不是说,创建了一个NodePort svc就会额外创建一个ClusterIP的svc,kubectl get service 还是1个,只是NodePort svc包含了对应ClusterIP svc的属性。
这里再说一下不常用的ExternalName类型的service,是将 Kubernetes Service 的 DNS 名称解析成外部的 DNS 名称,相当于给外部域名起了一个集群内部的别名。不会创建 ClusterIP、NodePort 或负载均衡器。不做流量代理,仅做 DNS CNAME 转换。
K8s 中,每个 Pod 启动时,kubelet 会自动为其配置 /etc/resolv.conf 文件,示例:
nameserver 10.32.0.10
search <namespace>.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
参数含义如下:
- nameserver:指定 DNS 服务器 IP(通常是 kube-dns/CoreDNS 的 ClusterIP)
- search:指定搜索域,用于补全非 FQDN 域名
- options ndots:n:控制 DNS 查询的补全策略。判断域名中点号数量,决定先作为 FQDN查询(>=n)还是先加 search 补全(<n)
FQDN(Fully Qualified Domain Name) 指 完全限定域名,如
www.example.com.,最后一个点表示.根域;与之对应的就是需要添加search进行补全的相对域名,关于 options ndots:n 的解释参看,https://www.ibm.com/docs/en/zos/3.1.0?topic=environments-options-ndots-statement
接下来,我们通过以下实验,类比 K8s 中 Pod 的 /etc/resolv.conf 配置,说明 DNS 查询扩展的机制,理解集群中DNS解析的过程。

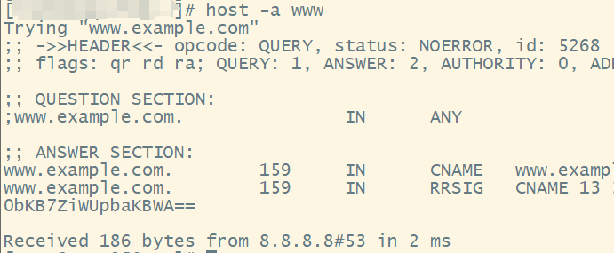
- 查询
www,点的数量小于1,添加example.com,查询www.example.com,成功
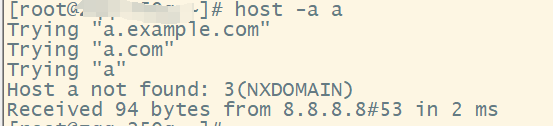
- 查询
a,点的数量小于1,添加example.com,查询a.example.com,失败;添加com,查询a.com,失败;最终将a最为FQDN查询,失败
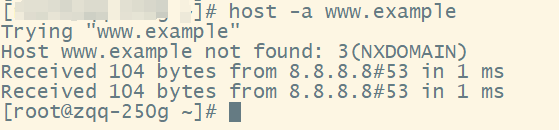
- 查询
www.example,点的数量大于等于1,直接作为FQDN查询,失败,且因为NXDOMAIN不补全 search(对NXDOMAIN的处理不同解析器实现可能存在差异)
- 查询
www.,因为结尾点的存在,本身就为FQDN,忽略search/options ndots:n进行查询,失败

K8s 会为service和pod分配DNS记录。
主要是以下2种形式的记录:
<service>.<namespace>.svc.<zone>.例子headless-svc.default.svc.cluster.local.<pod-ip>.<namespace>.pod.<zone>.例子10-244-0-4.default.pod.cluster.local.
以下yaml创建两个 Service,分别是 Headless Service(ClusterIP为None) 和 普通 ClusterIP Service 的示例,主要理解区别 DNS 解析行为的不同
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
app: my-app
ports:
- port: 8080
---
apiVersion: v1
kind: Service
metadata:
name: normal-svc
spec:
selector:
app: my-app
ports:
- port: 8080
# 创建以上yaml对应的svc
kubectl apply -f svc.yaml
# 查看svc分配的ClusterIP情况,headless-svc 的ClusterIP为None
kubectl get svc
# 查看svc对应的pod ip,后续发现 headless-svc 会直接解析到pod ip上
kubectl get ep
# 观察dns解析情况
kubectl exec -it http-log-demo -c log-reader -- /bin/sh
cat /etc/resolv.conf
# 直接解析到pod ip上
ping headless-svc
# 解析到对应的ClusterIP上
ping normal-svc
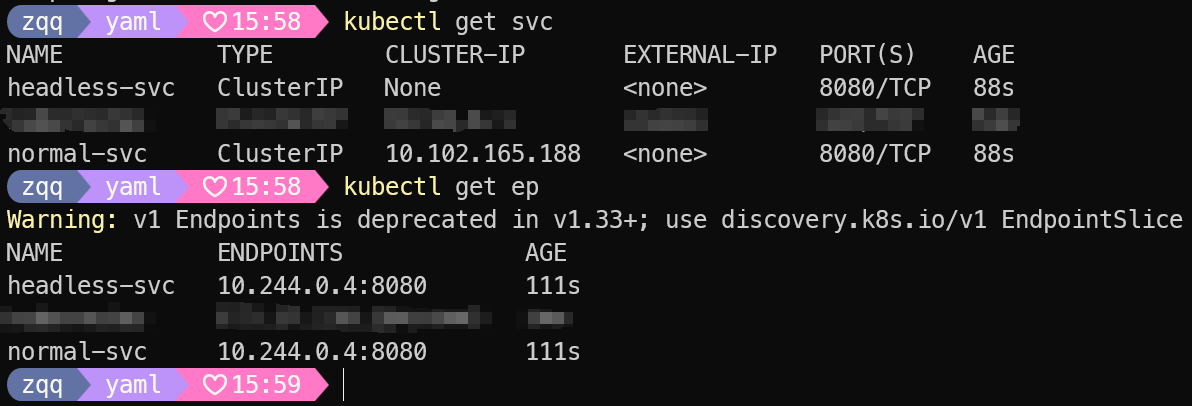
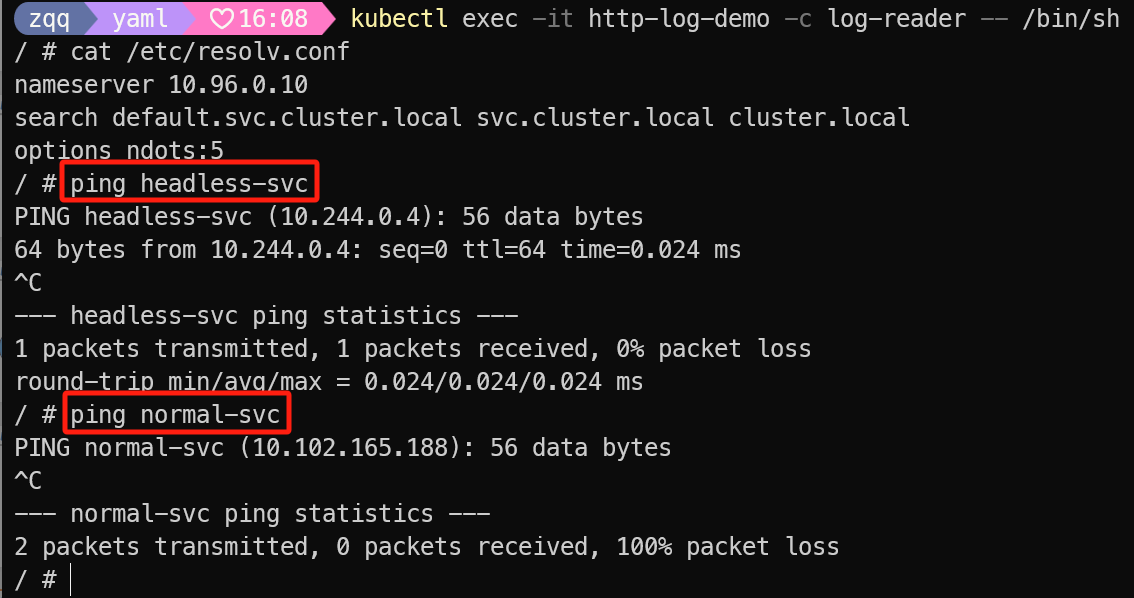
对 headless-service 做 dns 解析会直接返回 pod 的 ip,用于需要直接链接pod的场景,且不交由 kube-proxy 处理,一般搭配StatefulSet使用,后面说
1.7 PV/PVC #
我们先理解以下概念:

“Volume”一词源自拉丁语“volumen”,意为“一卷书”或“一个卷起的物体”,TCP/IP 卷一/卷二 也是用 Volume 这个单词,其他延伸含义表示各种形式的“量”或“体积”,空间占据量。 K8s中Volume 主要目的是 持久化存储 + 数据共享。
PV 抽象了底层存储的实现方式,例如:NFS/iSCSI/GlusterFS/CephFS/AWS EBS/GCE PD/CSI(容器存储接口)插件等,使用PV可以不用关心底层存储的实现;而 PVC 抽象了存储的使用方式:用户只管声明,不用考虑有没有,如何提供的问题。如“我要一个 5Gi 的卷,ReadWriteOnce 就行”,不关心后端怎么提供。PVC和PV是一对一的关系,一个 PVC 只能绑定一个 PV,且一旦绑定就不能解绑(除非删除PVC)。
在引入CSI(Container Storage Interface) 之前,K8s 的存储插件是内置(in-tree) 的,所有驱动代码直接合并到 Kubernetes 主仓库。会有一些问题:
- 这些插件由外部厂商进行开发,Kubernetes 主仓库管理起来很头疼
- 这意味着每次新增或更新插件,都要等待 Kubernetes 发版,流程复杂、开发缓慢
再看另外一个问题,为什么需要 StorageClass?
不同应用对存储的需求不同:
- Web 服务:普通性能磁盘即可
- 数据库:要求高 IOPS 和低延迟
- 日志归档:需要廉价的高容量存储
StorageClass 就是让管理员预先定义这些类型,而用户(开发者)只需在 PVC 中指定名称即可。同时,StroageClass 还能实现PV动态供给的功能,后面说。
如以下yaml定义了一个StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-ceph-block
provisioner: rbd.csi.ceph.com # CSI Driver Name
CSI Driver清单参看,https://kubernetes-csi.github.io/docs/drivers.html
使用PV/PVC过程中涉及到的各组件关系如下图:
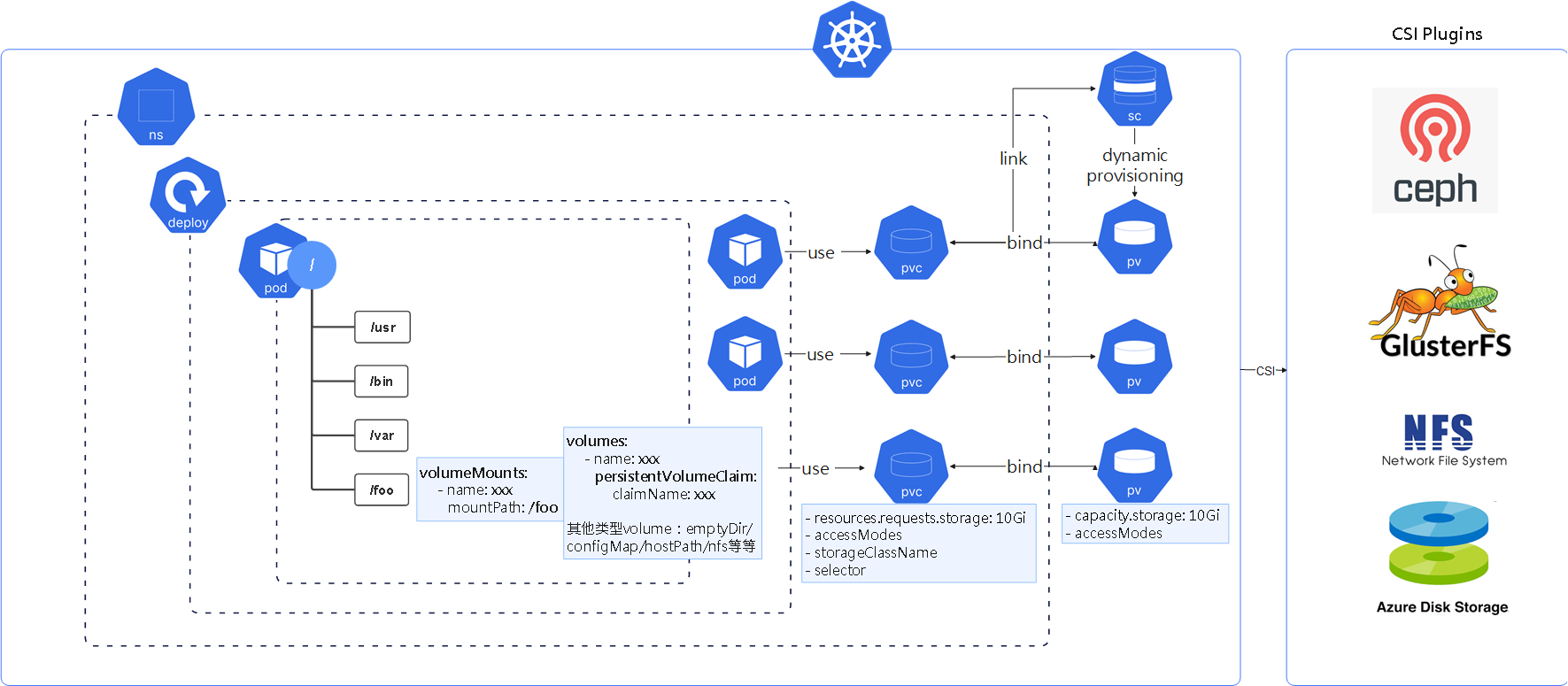
我们知道,Linux 目录结构是一个树状结构,可以通过mount将一个文件系统可以挂载到一个目录路径下,这个目录就成了这个文件系统的入口点。通过统一的目录结构,访问不同的文件系统。

容器类似,容器通过 volumeMounts将某个volume挂载到一个目录路径下,然后通过路径访问volume,volume可以理解为一个包含文件的目录或者块状设备。
volume 大致分为2个类型:
- ephemeral volume: 如emptyDir
- persistent volume
VC 发起绑定请求, PersistentVolumeController 控制器将其“绑定到”一个满足条件的 PV,满足条件涉及请求的空间、acessmode等方面;PV的创建方式主要有2种:静态和动态,我们也会在 StatefulSet 那里使用 volumeClaimTemplates 讲解一个动态创建的例子
动态方式解放了管理员,也解决了一些权限问题
- 创建 PV 需要 集群级别权限,只有管理员能做,不建议下放该权限
- 普通开发者一般只有特定namesapec权限,无权创建 PV,却能安全、合规地获得 PV 使用权,将“创建 PV 的权限”封装在控制器代码中
如以下yaml,先创建StorageClass,后直接创建PVC,会自动创建对应绑定的PV,实现PV的动态供给
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-storage
provisioner: rbd.csi.ceph.com # CSI 插件名称
parameters:
pool: kube-pool
imageFormat: "2"
imageFeatures: layering
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: fast-storage
StorageClass 定义中必须指定
provisioner,实际存储需要由 Provisioner 来实现,需要额外部署对应的存储插件或 CSI 驱动StorageClass中reclaimPolicy的含义: 决定当 PVC 被删除时,关联的 PV 和底层存储(比如磁盘、目录等)是否也自动删除,它影响的是 StorageClass 创建的 PV 的 persistentVolumeReclaimPolicy 字段默认值