1 容器特征 #

先尝试总结一下容器的一些特征,如下:
- 每个容器可以有独立的主机名

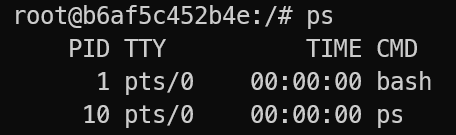
- 容器内进程从
PID=1开始编号,拥有自己的进程树
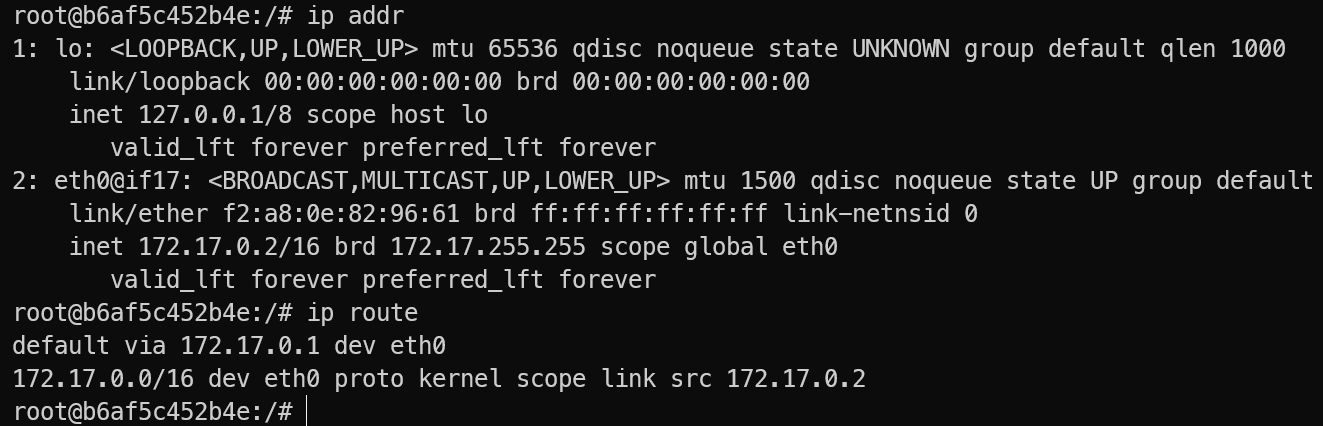
- 容器拥有独立的网络栈(独立的
lo,独立的 IP、端口空间、路由表)
- 容器内的
/看起来是一个完整的 Linux 文件系统,rootfs,有独立的挂载点视图

- 容器和宿主机使用的是一个内核

2 namespace #
namespace是 Linux 内核在 2.6.24 (2008) 引入的特性,它的作用是给进程提供 各种不同的视图,使得不同的进程互相隔离。虚拟机需要硬件层模拟,而容器直接复用宿主机内核,容器的性能优势很大,容器的隔离性主要依赖 namespace 实现。
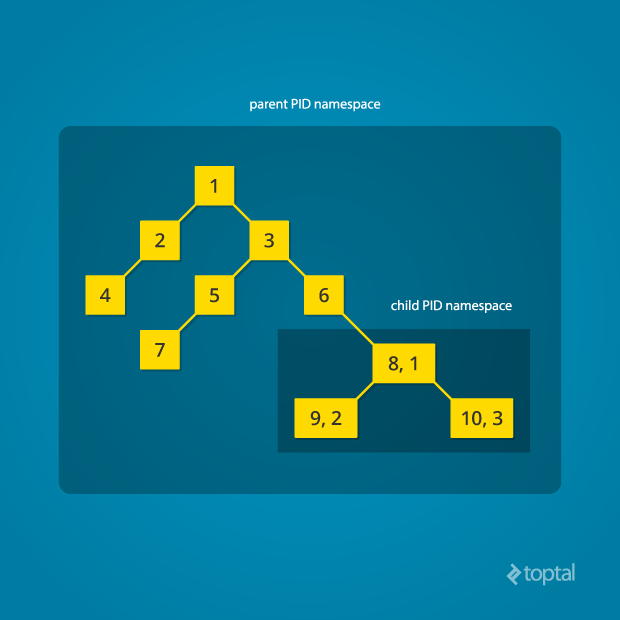
Linux Kernel 5.7 包含了 七大 namespace 类型:
PID namespace- 隔离系统进程树,容器里
ps看到的 PID 是从 1 开始的,但在宿主机上它对应另一个 PID
- 隔离系统进程树,容器里
NET namespace- 隔离网络栈(IP 地址、路由表、防火墙规则、网络设备),每个容器都可以有自己独立的虚拟网卡、IP、路由
MNT namespace- 隔离挂载点,不同的 namespace 可以看到不同的文件系统结构,比如容器里的根目录
/,和宿主机的/不是同一个
- 隔离挂载点,不同的 namespace 可以看到不同的文件系统结构,比如容器里的根目录
UTS namespace- 隔离主机名,容器内部可以有自己独立的 hostname,不会影响宿主机
IPC namespace- 隔离进程间通信(共享内存、信号量),避免容器进程通过 IPC 与宿主机或其他容器干扰
USER namespace- 隔离用户和用户组 ID,容器里的 root 用户(UID 0)可以映射到宿主机的普通用户,从而避免真正的 root 权限泄露
CGROUP namespace- 隔离 cgroup 文件系统的视图,每个 namespace 可以看到自己可用的 cgroup,而不是宿主机的完整 cgroup,主要用于资源限制(CPU、内存、IO),新建的 cgroup namespace 的“根视图”= 创建它的进程当时所在的 cgroup
理解:进程必须隶属于某个 namespace,默认情况下,子进程会继承父进程的所有 namespace 引用
比如,进程所在的 UTS namespace 决定了它调用
gethostname()时能看到的值。如果两个进程在不同的 UTS namespace,就可以看到不同的 hostname。由于默认情况下,子进程会继承父进程的所有 namespace 引用,所以同一个容器内,看起来所有进程namespace视图是一样的,即 hostname 是一样的。
3 cgroup #
默认docker run方式运行的容器是不会添加cpu/memory资源限制的,只是被 namespace 隔离了视图。可能会存在容器将宿主机资源占用完的情况。
可以使用以下命令运行时进行资源限制:

数值:50000 100000 的解读
quota = 50000 µs (50ms),period = 100000 µs (100ms)
在 100ms 内,容器最多只允许跑 50ms → 50% 的 CPU 带宽。
单核 CPU,容器最多只能使用一半的 CPU。
多核 CPU:如果宿主有 4 核,那么容器最多用
0.5 × 4 = 2 核心的算力。
cgroup (control groups) 是 Linux 内核提供的一种 资源限制机制,可以限制 CPU 占用、内存使用量,它需要一个 用户态接口 来管理。
Linux 一直遵循 一切皆文件 的哲学,所以内核把 cgroup 的接口 以文件系统的形式暴露出来。内核为了让用户能操作它,把 cgroup 的控制接口抽象成了一个 虚拟文件系统,需要先挂载,比如挂载到/sys/fs/cgroup目录,即告诉内核要在 /sys/fs/cgroup 目录下展示 cgroup 这个接口,挂载完成后,目录下才会出现那些 cpu.max、memory.max 这样的文件,然后通过写入不同的值进行调整。
在 Linux 中,你可以挂载一个 cgroupfs 或者 cgroup2 文件系统(cgroup v2),现在主流 Linux 发行版(如 Debian 11+/Ubuntu 20.04+)默认用的是 cgroup v2。。挂载点通常是:
- v1:
/sys/fs/cgroup/<controller>/... - v2:
/sys/fs/cgroup/
如下命令查看cgroup v2 挂载点
mount | grep cgroup2

在 Linux 里,常规理解 挂载(mount) = 把一个 文件系统的实现 连接到 用户空间的目录树。只有挂载之后,用户态才能以文件/目录的方式访问这些内容。
比如:
- 把一个磁盘分区的 ext4 文件系统挂载到
/mnt/disk其实,挂载(mount)在 Linux 中不只是针对磁盘文件系统,而是可以把任何内核提供虚拟文件系统挂载到某个目录。
比如:
/proc是 procfs,提供进程信息接口(并不是硬盘上的东西)/sys是 sysfs,提供设备和内核参数信息- /sys/fs/cgroup 就是 cgroupfs/cgroup2,提供资源控制接口
通过挂载虚拟文件系统,然后修改/查看文件的方式,实现了用户态程序与内核之间的交互,如修改内核参数,查看进程信息,设置资源控制等。这是Linux 一切皆文件 哲学的重要体现
4 容器创建本质 #
我们整理一下,docker容器创建时大致做了以下操作,供参考:
执行
docker run --memory=512m --cpus=0.5,Docker Daemon 会在宿主机的/sys/fs/cgroup下为容器创建一个子目录,表示一个cgroup子树,例如:/sys/fs/cgroup/system.slice/docker-<container-id>.scope宿主机侧写入限制
echo 536870912 > /sys/fs/cgroup/system.slice/docker-<container-id>.scope/memory.max # 限制内存 512MB echo "50000 100000" > /sys/fs/cgroup/system.slice/docker-<container-id>.scope/cpu.max # 限制 0.5CPU把容器进程的 PID 加入到这个 cgroup
echo <pid> > /sys/fs/cgroup/system.slice/docker-<container-id>.scope/cgroup.procs
CGROUP namespace,宿主机的/sys/fs/cgroup是完整的,但在容器里却是裁剪的,避免容器看到其他挂载情况;核心规则是:新cgroup命名空间的“视图根” = 创建它的那个进程当时所在的 cgroup,cgroup.procs的值也会自动更新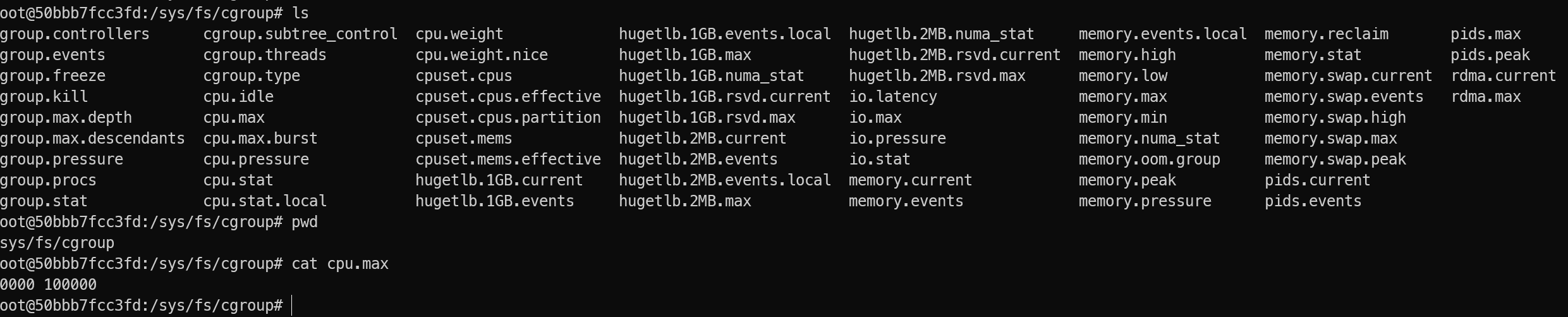

CGROUP namespace,控制“容器认为自己在 cgroup 树的什么位置”,避免容器里的进程看到自己属于/system.slice/docker-<container-id>.scope,泄露真实路径,而是让容器认为自己就在/,以为自己是 cgroup 的根

5 模拟容器 #
通过以下步骤手动模拟一个容器
5.1 准备rootfs #
可以使用 alpine 提供的mini rootfs

$ pwd
/home/zqq/demo-container
$ wget https://dl-cdn.alpinelinux.org/alpine/v3.22/releases/x86_64/alpine-minirootfs-3.22.1-x86_64.tar.gz
$ mkdir rootfs
$ tar zxvf -C rootfs alpine-minirootfs-3.22.1-x86_64.tar.gz
$ tree -L 1 rootfs
rootfs
├── bin
├── dev
├── etc
├── home
├── lib
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin
├── srv
├── sys
├── tmp
├── usr
└── var
17 directories, 0 files

5.2 创建 cgroup v2 并设置资源限制 #
$ CG=/sys/fs/cgroup/demo-container
$ sudo mkdir -p $CG
# 限制:最多 100M 内存
$ echo $((100*1024*1024)) | sudo tee $CG/memory.max
# CPU:配 50% (周期100000、配额50000微秒)
$ sudo echo "50000 100000" | sudo tee $CG/cpu.max
5.3 启动一个完整隔离的命名空间 #
# 先把当前 shell 放进这个 cgroup
# 新cgroup命名空间的“视图根” = 创建它的那个进程当时所在的 cgroup
$ echo $$ | sudo tee "$CG/cgroup.procs"
$ ROOTFS=/home/zqq/demo-container/rootfs
$ exec unshare --fork --pid --mount --cgroup --uts --ipc --net bash -c '
set -e
# 1) UTS:设置容器内主机名
hostname demo-container
# 2) Mount:让 mount 命名空间独立、私有
mount --make-rprivate /
# 为了更干净,切换到我们准备的 rootfs(chroot 前先绑定必要目录)
mount -t proc proc '"$ROOTFS"'/proc
mount -t sysfs sysfs '"$ROOTFS"'/sys
mount -t tmpfs tmpfs '"$ROOTFS"'/dev
mount -t tmpfs tmpfs '"$ROOTFS"'/tmp
mount -t cgroup2 none '"$ROOTFS"'/sys/fs/cgroup
# 提供必须的设备节点(最小集合)
mknod -m 666 '"$ROOTFS"'/dev/null c 1 3
mknod -m 666 '"$ROOTFS"'/dev/zero c 1 5
mknod -m 666 '"$ROOTFS"'/dev/tty c 5 0
mknod -m 666 '"$ROOTFS"'/dev/random c 1 8
mknod -m 666 '"$ROOTFS"'/dev/urandom c 1 9
# 3) chroot 切根(模拟容器根文件系统)
chroot '"$ROOTFS"' /bin/sh -c "
set -e
echo \"[demo-container] hostname:\$(hostname)\"
echo \"[demo-container] mounts:\"
mount | head -n 5
# 4) 在新的 PID 命名空间里启动 init 进程(/bin/sh)
# 注意:因为 --pid 已经用 --fork 打开,当前 shell 是 PID 1。
echo \"[demo-container] I am PID: \$$\"
# 5) 在容器内启动一个前台 shell,便于交互
exec /bin/sh
"
'
# 启动后,在宿主找到父进程 PID,然后把它迁到别的 cgroup(例如根):
$ P=$(ps -eo pid,ppid,cmd | awk '/^ *[0-9]+ .* unshare --fork/{print $1; exit}')
$ echo $P | sudo tee /sys/fs/cgroup/cgroup.procs

5.4 验证cgroup生效 #
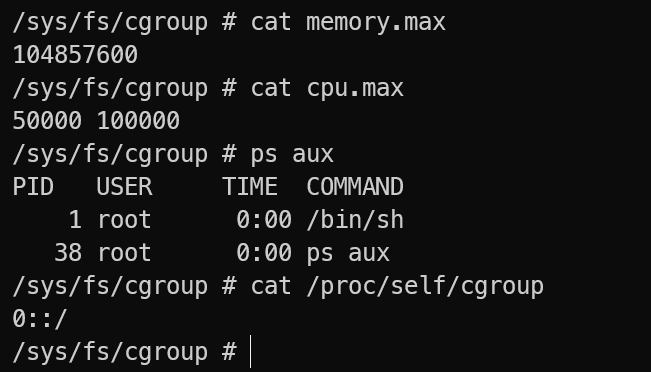
5.5 网络命名空间 + veth 配置 #
容器和宿主机网络互相访问
宿主机操作:
# 先找出容器内 /bin/sh 的网络命名空间对应的宿主 PID
$ ps aux | grep sh
$ sudo ip link add veth0 type veth peer name vethc
$ sudo ip link set vethc netns 602
$ sudo ip addr add 10.0.0.1/24 dev veth0
$ sudo ip link set veth0 up
容器内操作:
# 发现多了一张 vethc 网卡
$ ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
17: vethc@if18: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 8e:4b:f3:cc:ef:e1 brd ff:ff:ff:ff:ff:ff
$ ip link set lo up
$ ip addr add 10.0.0.2/24 dev vethc
$ ip link set vethc up
$ ping -c 3 10.0.0.1
PING 10.0.0.1 (10.0.0.1): 56 data bytes
64 bytes from 10.0.0.1: seq=0 ttl=64 time=0.084 ms
64 bytes from 10.0.0.1: seq=1 ttl=64 time=0.056 ms
^C
--- 10.0.0.1 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.056/0.070/0.084 ms
veth (Virtual Ethernet pair) 是内核提供的一种虚拟网络设备,成对出现。
特性:
- 数据写入一端会从另一端出来,像一条“虚拟网线”,这里指的是 L2 层的帧传递
- 每个端口都可以配置 IP/MAC、加到不同的 namespace 里
- 常用于连接 容器网络命名空间 ↔ 宿主机/bridge
在 Docker 里,容器里的
eth0实际上就是一对 veth 的一端,另一端放进宿主的网桥(docker0)
此时网络拓扑如下:
┌─────────────────────────┐
│ 宿主机 Namespace │
│ veth0 (10.0.0.1/24) │
│ │
└────────────┬────────────┘
│
(veth pair)
│
┌────────────┴────────────┐
│ │
│ vethc (10.0.0.2/24) │
│ 容器 Namespace │
└─────────────────────────┘
如果需要访问外网,可以在宿主开 IP 转发 + NAT:
$ sudo sysctl -w net.ipv4.ip_forward=1
$ iptables -t nat -A POSTROUTING -s 10.0.0.0/24 -j MASQUERADE
容器 Namespace
┌─────────────────────────┐
│ │
│ vethc: 10.0.0.2/24 │
│ Default GW: 10.0.0.1 │
│ │
└────────────┬────────────┘
│
(veth pair)
│
┌────────────┴────────────┐
│ │
│ veth0: 10.0.0.1/24 │
│ │
│ 宿主机 Namespace │
│ (开启 IP_FORWARD) │
│ │
│ [iptables NAT] |
│ SNAT 10.0.0.0/24 → |
|宿主机IP (192.168.1.100) |
│ │
└────────────┬────────────┘
│
┌──────────┴───────────┐
│ │
宿主机外网接口 eth0 (192.168.1.100/24)
│
▼
┌─────────────────┐
│ 外部网络/Internet │
└─────────────────┘
容器内再测试:
$ ip route add default via 10.0.0.1 dev vethc
$ ping -c 3 8.8.8.8
ping -c 3 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=110 time=36.924 ms
64 bytes from 8.8.8.8: seq=1 ttl=110 time=36.659 ms
64 bytes from 8.8.8.8: seq=2 ttl=110 time=36.792 ms
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 36.659/36.791/36.924 ms
$ printf 'nameserver 8.8.8.8\n' > /etc/resolv.conf
$ curl www.baidu.com
5.6 其他说明 #
以上只是模拟,并不代表实际的过程,实际的过程复杂得多,如OverlayFS:给 rootfs 叠一层可写层,镜像层叠与“写时复制”、更复杂的容器网络等等