杂项中的压缩包主要为rar和zip格式,这2种格式的magic number如下:
rar:52 61 72 21 1A 07 00:Rar!, Roshal ARchive compressed archive v1.50 onwards
zip:50 4B 03 04:PK␃␄, zip/apk/docx/pptx/jar等文件本质都是zip格式,都使用这个头
可以简单识别为是否包含Rar!和PK等关键字,详细请参看 https://en.wikipedia.org/wiki/List_of_file_signatures
暴力破解 #
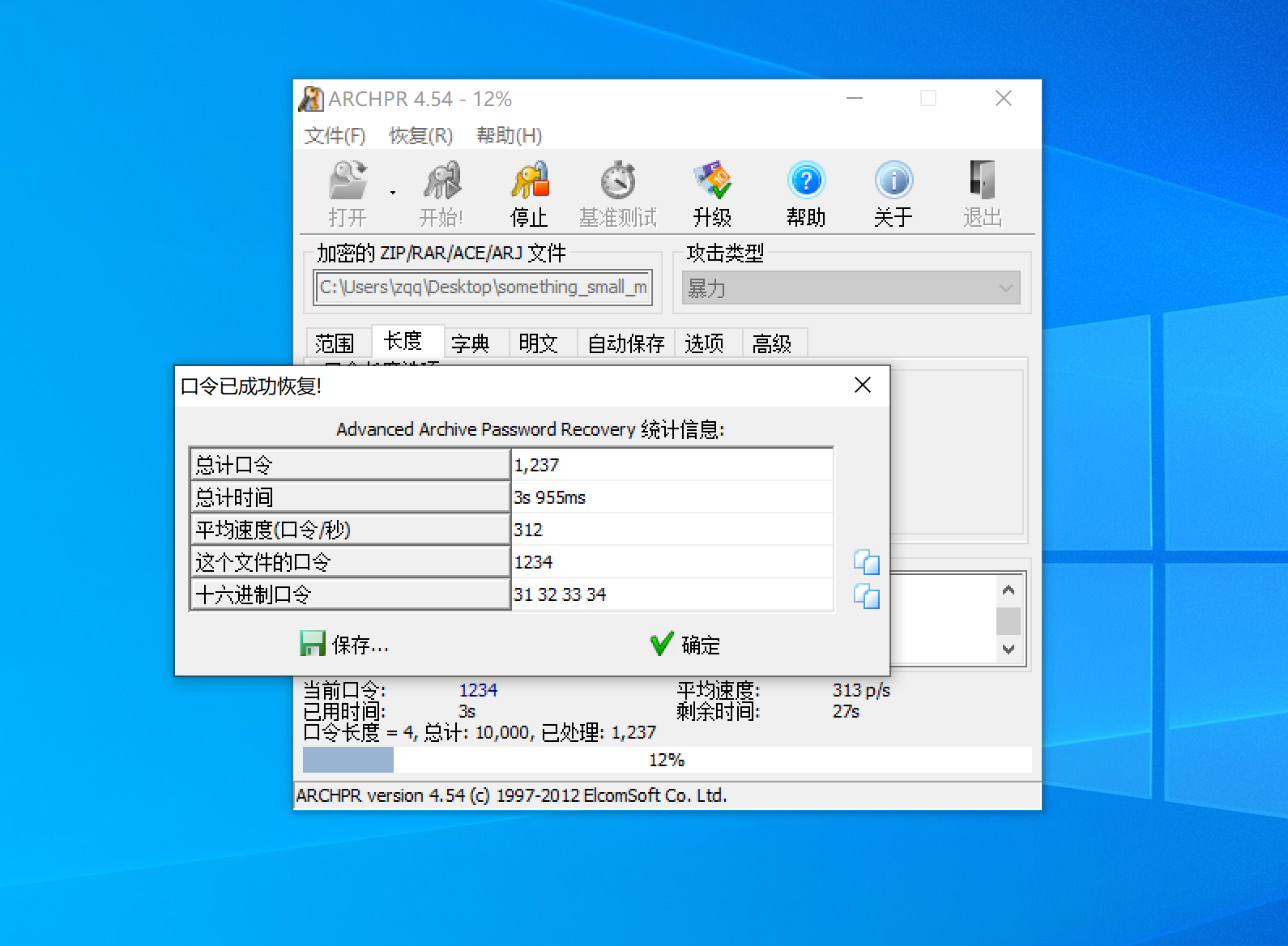
当使用弱口令对压缩包进行加密时,可以使用John the Ripper或ARCHPR工具
使用john爆破rar,发现弱口令为1234
# rar2john something_small_make_me_bigger.rar > hash.txt
# cat hash.txt
something_small_make_me_bigger.rar:$RAR3$*1*3b980ea023103f1a*9662d9a4*160*205*1*1c12ac513b1b8ebe3a799bcf5607ef8b32797a897c546d9184dae4d12277143e3d7d69996c4761f48a213bad8ee34176f8b766e9daa20c2d9783d97c2417f785a3bc9d2621dfe4ec08b481cad8611456ceeafecd680fdc96ba1e04ee01e453b719656b6a550f782272e33df6da572e9e1ca3f2ef5d33d0711ebe27c13928171cf6194b17c5c1190991b2d1af5b6d70d3e0115a958fd76cd7467f951bdb1dffbb*33:1::something_small_make_me_bigger.txt
# john --incremental=LowerNum hash.txt
john --incremental=LowerNum hash.txt
Using default input encoding: UTF-8
Loaded 1 password hash (rar, RAR3 [SHA1 256/256 AVX2 8x AES])
Will run 4 OpenMP threads
Press 'q' or Ctrl-C to abort, almost any other key for status
1234 (something_small_make_me_bigger.rar)
1g 0:00:00:02 DONE (2023-10-05 11:36) 0.5000g/s 416.0p/s 416.0c/s 416.0C/s 123456..manny1
Use the "--show" option to display all of the cracked passwords reliably
Session completed.
zip类似,使用zip2john代替rar2john
ARCHPR爆破rar,发现弱口令为1234
伪加密 #
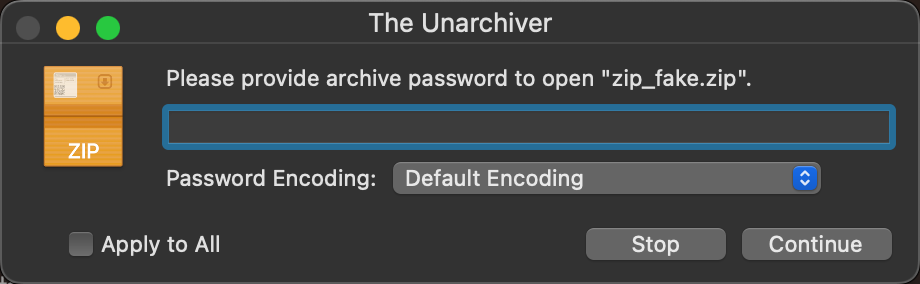
zip/rar文件中有字段标识了该文件是否被加密,伪加密的含义是文件内容实际没有被加密,仅是否被加密的标识被修改,找到对应字段修改加密标识即可
如下解压提示需要密码,但没有给其他信息,则推测可能是伪加密
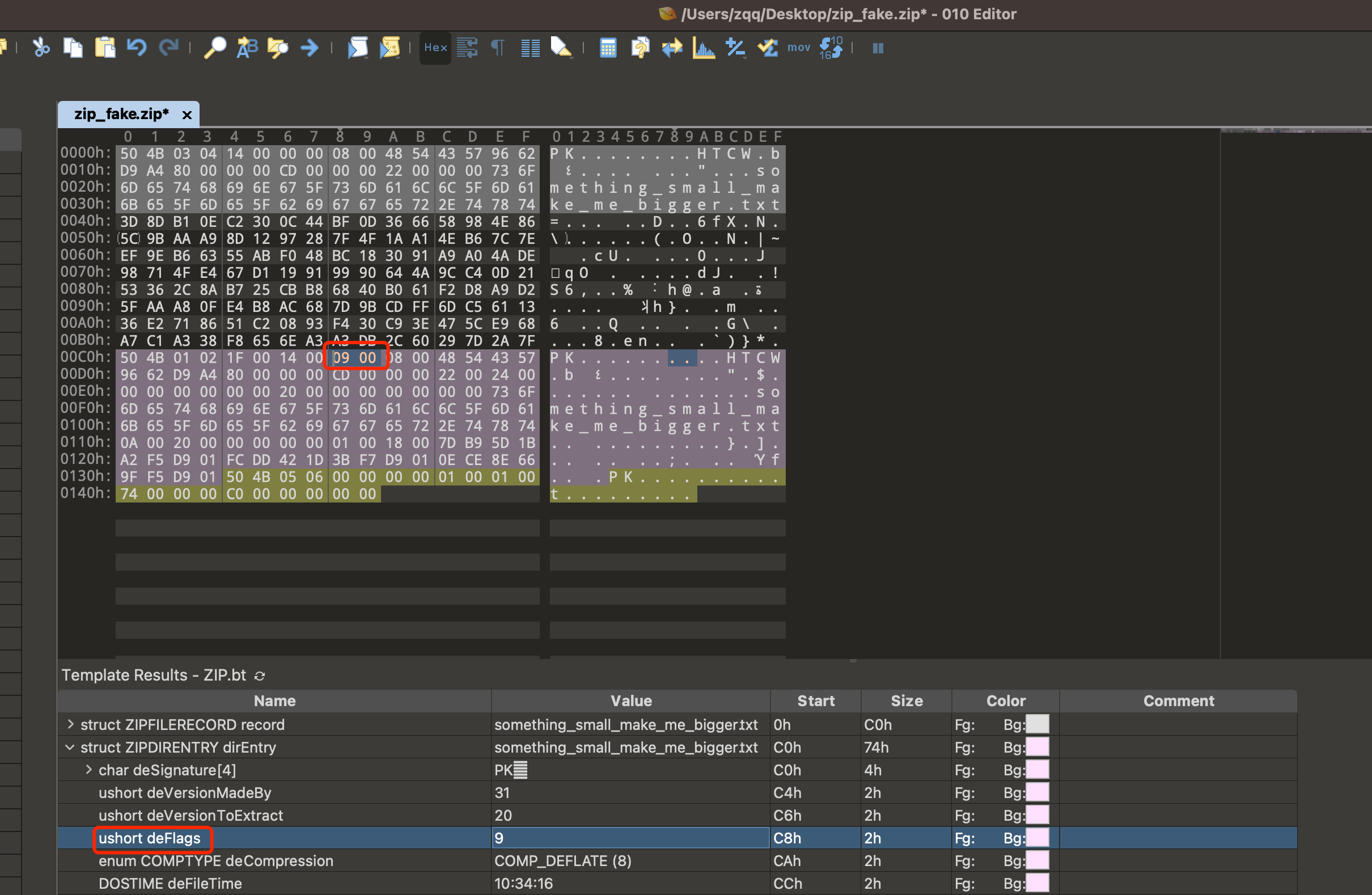
zip文件格式分为以下3部分:
ZIPFILERECORD: 文件记录区ZIPDIRENTRY: 文件目录区,deFlags标识是否加密,00 00标识未加密,00 09标识加密ZIPENDLOCATOR: 文件结束标志
010Editor打开修改字段如下:
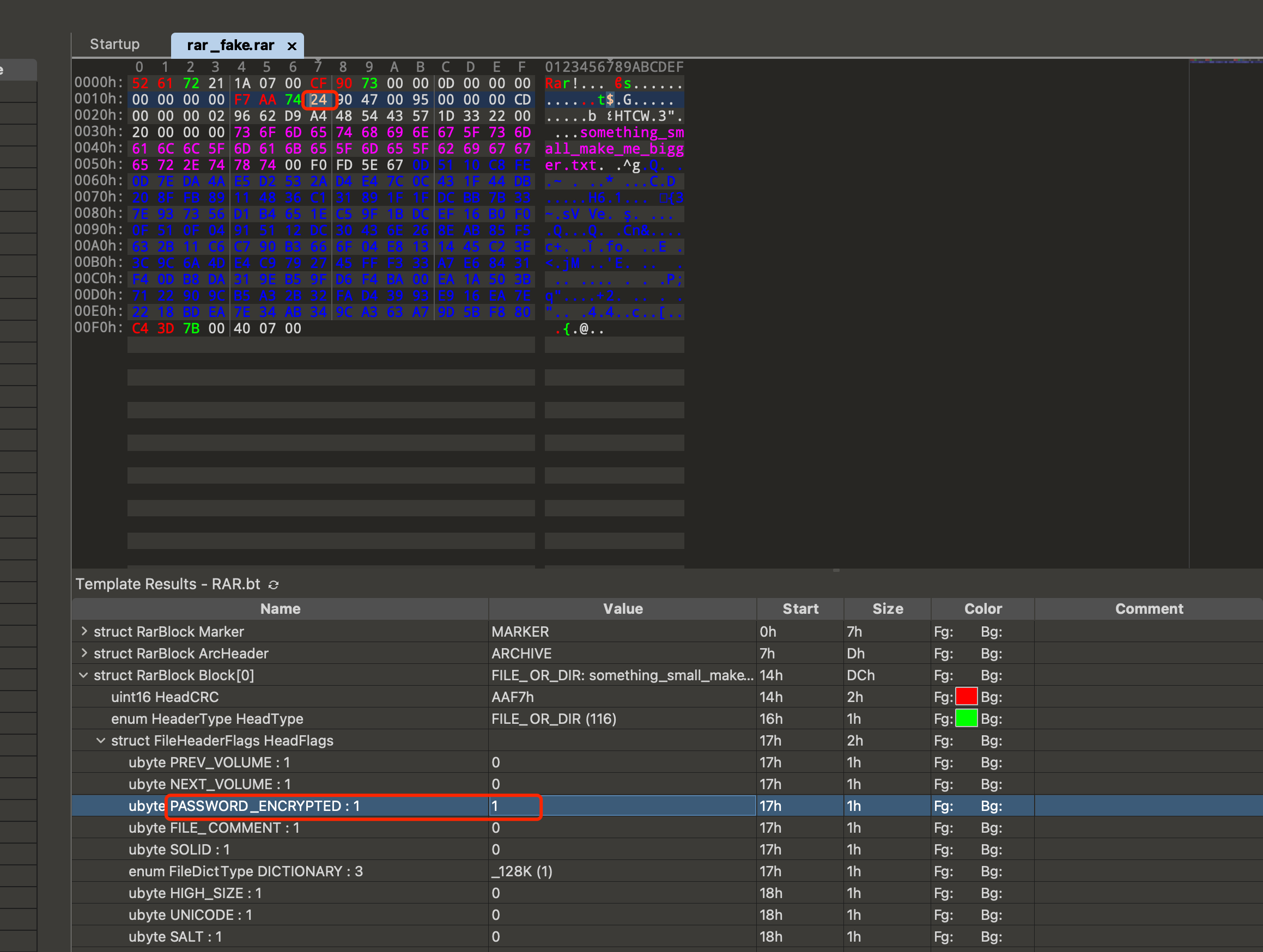
rar文件格式分为很多个块:
Marker: 标记块ArcHeader: 归档头块,PASSWORD_ENCRYPTED : 0表示未加密,PASSWORD_ENCRYPTED : 1标识加密Block: 文件块
010Editor打开修改字段如下:
crc32碰撞 #
CRC的全称是循环冗余校验。为了保证解压后数据正确,压缩包中的每个文件都有一个CRC32bit的值,即便数据中一个bit发生变化,也会导致CRC32值不同
若是知道一段数据的长度和CRC32值,便可穷举数据,与其CRC32对照,以此达到暴力猜解的目的,但通常只适用于较小文本文件,如大小小于6字节的文本文件
如
python crc32_reverse.py -c 0x352441c2 -n 3
[find]: abc (OK)
脚本如下:
# -*- coding: utf-8 -*-
import zipfile
import binascii
import itertools
import struct
import string
class crc32_reverse_class(object):
# the code is modified from https://github.com/theonlypwner/crc32/blob/master/crc32.py
def __init__(self, crc32, length, tbl=string.printable,
poly=0xEDB88320, accum=0):
self.char_set = set(map(ord, tbl))
self.crc32 = crc32
self.length = length
self.poly = poly
self.accum = accum
self.table = []
self.table_reverse = []
def init_tables(self, poly, reverse=True):
# build CRC32 table
for i in range(256):
for j in range(8):
if i & 1:
i >>= 1
i ^= poly
else:
i >>= 1
self.table.append(i)
assert len(self.table) == 256, "table is wrong size"
# build reverse table
if reverse:
found_none = set()
found_multiple = set()
for i in range(256):
found = []
for j in range(256):
if self.table[j] >> 24 == i:
found.append(j)
self.table_reverse.append(tuple(found))
if not found:
found_none.add(i)
elif len(found) > 1:
found_multiple.add(i)
assert len(self.table_reverse) == 256, "reverse table is wrong size"
def rangess(self, i):
return ', '.join(map(lambda x: '[{0},{1}]'.format(*x), self.ranges(i)))
def ranges(self, i):
for kg in itertools.groupby(enumerate(i), lambda x: x[1] - x[0]):
g = list(kg[1])
yield g[0][1], g[-1][1]
def calc(self, data, accum=0):
accum = ~accum
for b in data:
accum = self.table[(accum ^ b) & 0xFF] ^ ((accum >> 8) & 0x00FFFFFF)
accum = ~accum
return accum & 0xFFFFFFFF
def findReverse(self, desired, accum):
solutions = set()
accum = ~accum
stack = [(~desired,)]
while stack:
node = stack.pop()
for j in self.table_reverse[(node[0] >> 24) & 0xFF]:
if len(node) == 4:
a = accum
data = []
node = node[1:] + (j,)
for i in range(3, -1, -1):
data.append((a ^ node[i]) & 0xFF)
a >>= 8
a ^= self.table[node[i]]
solutions.add(tuple(data))
else:
stack.append(((node[0] ^ self.table[j]) << 8,) + node[1:] + (j,))
return solutions
def dfs(self, length, outlist=['']):
tmp_list = []
if length == 0:
return outlist
for list_item in outlist:
tmp_list.extend([list_item + chr(x) for x in self.char_set])
return self.dfs(length - 1, tmp_list)
def run_reverse(self):
# initialize tables
self.init_tables(self.poly)
# find reverse bytes
desired = self.crc32
accum = self.accum
# 4-byte patch
if self.length >= 4:
patches = self.findReverse(desired, accum)
for patch in patches:
checksum = self.calc(patch, accum)
print 'verification checksum: 0x{0:08x} ({1})'.format(
checksum, 'OK' if checksum == desired else 'ERROR')
for item in self.dfs(self.length - 4):
patch = map(ord, item)
patches = self.findReverse(desired, self.calc(patch, accum))
for last_4_bytes in patches:
if all(p in self.char_set for p in last_4_bytes):
patch.extend(last_4_bytes)
print '[find]: {1} ({0})'.format(
'OK' if self.calc(patch, accum) == desired else 'ERROR', ''.join(map(chr, patch)))
else:
for item in self.dfs(self.length):
if crc32(item) == desired:
print '[find]: {0} (OK)'.format(item)
def crc32_reverse(crc32, length, char_set=string.printable,
poly=0xEDB88320, accum=0):
'''
:param crc32: the crc32 you wnat to reverse
:param length: the plaintext length
:param char_set: char_set
:param poly: poly , default 0xEDB88320
:param accum: accum , default 0
:return: none
'''
obj = crc32_reverse_class(crc32, length, char_set, poly, accum)
obj.run_reverse()
def crc32(s):
'''
:param s: the string to calculate the crc32
:return: the crc32
'''
return binascii.crc32(s) & 0xffffffff
def getcrc(file):
crclist = []
zipFile = zipfile.ZipFile(file)
for info in zipFile.infolist():
crclist.append(info.CRC)
return crclist
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-c' ,'--crc32', help='specify crc32 value')
parser.add_argument('-f' ,'--file', help='specify archive file path')
parser.add_argument('-n' ,'--number', help='specify the byte number, suggested < 6', type=int)
args = parser.parse_args()
# print(args.file)
# print(args.crc32)
# print(args.number)
# print(type(args.number))
if len(args.crc32) > 0:
crc32_reverse(int(args.crc32,16),args.number)
else:
crclist = getcrc(args.file)
for i in crclist:
crc32_reverse(i,args.number)
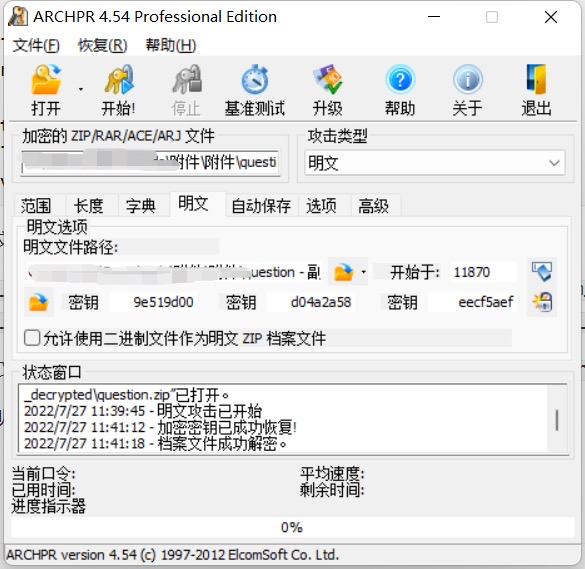
zip已知明文攻击 #
这种攻击是基于 Biham 和 Kocher 在 94 年发表的论文《A Known Plaintext Attack on the PKZIP Stream Cipher》实现的
明文攻击主要利用大于12字节的一段已知明文数据进行攻击,从而获取整个加密文档的数据
也就是说,如果手里有一个未知密码的压缩包和压缩包内某个文件的一部分明文(不一定非要从头开始,能确定偏移就行),那么就可以通过这种攻击来解开整个压缩包
比如压缩包里有一个常见的 license 文件,或者是某个常用的 dll 库,或者其他方式得到了压缩包中的一个文件内容,那么就可以运用这种攻击。当然,前提是压缩包要用 ZipCrypto 加密
工具层面可以使用 ARCHPR 或 bkcrack 简单完成破解,ARCHPR准备一个包含明文的压缩包(具体限制可以参考下面第二个链接文章)
https://flandre-scarlet.moe/blog/1685/
https://www.poboke.com/crack-encrypted-zip-file-with-plaintext-attack.html