个人理解,解决web题目的过程,可以视为一种信息收集与知识应用的过程;未能收集到足够的关键信息或者解决问题的立脚点涉及到知识盲区,都会导致问题无法解决。
下面列举了题目开始阶段收集信息的固定方式和相关工具。
题干信息 #
不要忽略了题目给的提示或信息
查看源代码 #
右键 View Page Source 查看网页源代码,查看是否有一些无法显示在页面中的注释信息;F12 Network 查看请求 response,有时也包含源代码不会展示的信息
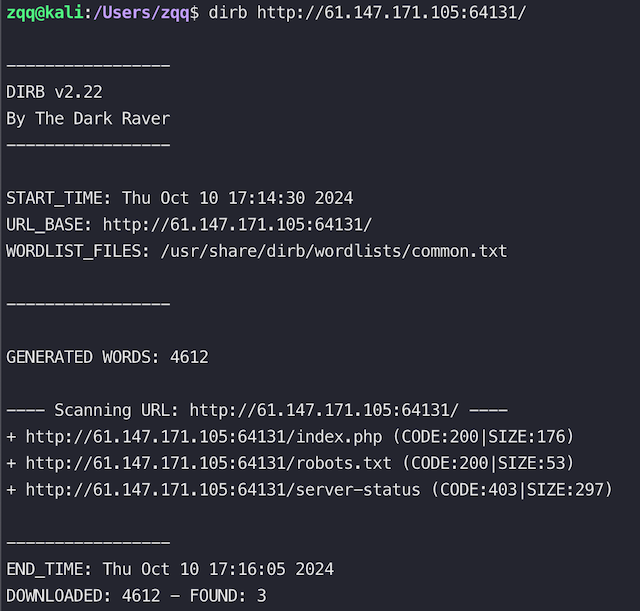
目录扫描 #
kali 上可以使用 dirb 进行目录爆破,可能能够发现一些额外页面,如robots.txt,后台管理页面等,个人建议可以上来无脑扫一下,花费不了多少时间
备份文件/源码文件等 #
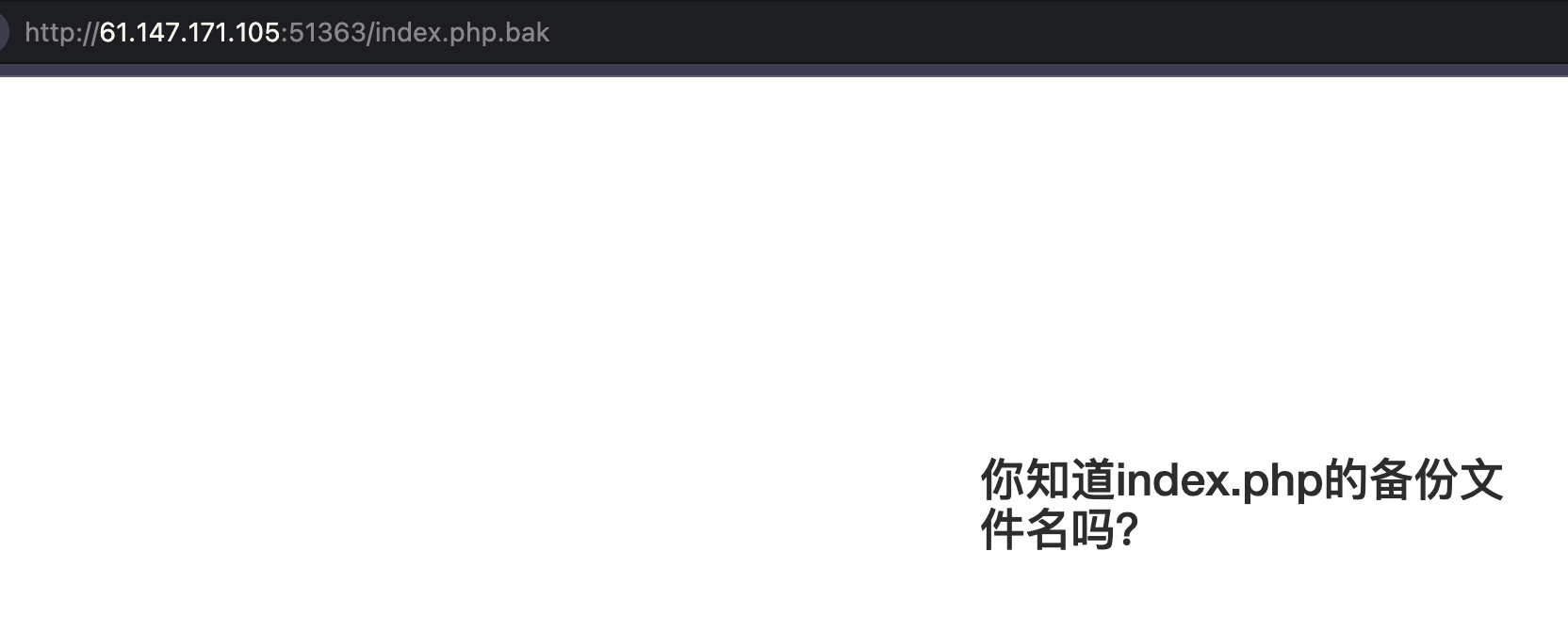
有明显提示备份文件等,可以通过类似index.php.bak获取源码备份文件,可近一步分析源码逻辑
其他常见备份文件名后缀:.swp .phps .zip .rar 等等
phps文件就是php的源代码文件,通常用于提供给用户(访问者)直接通过Web浏览器查看php代码的内容。 因为php代码会被web服务器执行,用户无法直接通过Web浏览器“看到”php文件的内容,所以需要用phps文件代替
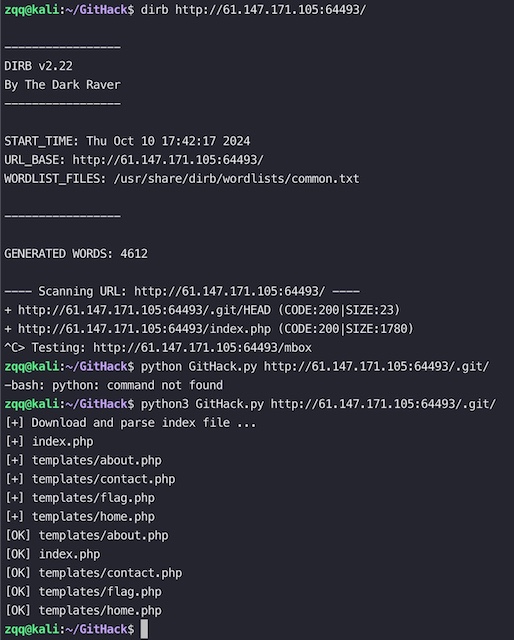
如果目录扫描包含.git目录,说明可能存在源代码泄漏,可以通过 Githack 工具 dump 泄漏的代码到本地
网站语言组件信息 #
kali 上可以使用 whatweb 查看网站使用的编程语言(主要为php/python)、web组件等信息

除了以下公共题型:
- 命令执行
- sql注入
- 反序列化
- 代码审计
语言特有题型如下:
- php: 文件包含,文件上传
- python: SSTI
- node: 原型链污染