导航 #
HTTP发展 #
WWW #
Tim Berners-Lee,万维网(World Wide Web)的发明者,2016年获图灵奖。1990年定义HTTP、HTML、URL三项关键技术,同年12月25日完成首个Web服务器与浏览器的通信。1991年创建世界上第一个网站 info.cern.ch,1994年创立W3C推动技术标准化。
互联网(Internet)作为网络基础设施,早在 1960-70 年代就以 ARPANET 的形式存在了,主要用于军事和学术机构之间传输数据。到 1980 年代已经有相当规模,但用起来需要专业知识,普通人完全摸不着头脑。WWW技术给互联网赋予了强大的生命力,Web浏览的方式给了互联网靓丽的青春。
HTML = Hypertext Markup Language
HTTP = Hypertext Transfer Protocol其中 Hypertext 的含义:
文本里嵌入了可跳转的链接,点击某个词或句子可以直接跳到另一个文档或位置,而不是像书一样只能线性地从头读到尾。“超”(hyper)的意思就是超越线性,打破了传统文本只能顺序阅读的限制。这个概念最早来自 Ted Nelson。万维网中的关键技术:
- HTML: 用于表示超文本的文本格式
- HTTP: 用于交换这些文本的协议
- 浏览器:用于显示(和编辑)这些文档的客户端,第一个浏览器,名为WorldWideWeb
- 服务器:用于提供文档访问的服务器,是 httpd 的早期版本
版本历史 #
- HTTP/0.9
- 初始版本,当时无版本号,0.9是后续为了区分加的
- 一行协议,只支持GET方法,
GET /my-page.html,响应只有一个html文件<html>xxx</html> - 没有HTTP headers,错误需包含在响应中的html中
- HTTP/1.0 RFC 1945,先有事实标准,RFC更像是整理总结
- 请求和响应中加入了HTTP headers,版本信息
- 响应中加入了响应码
- 只支持GET、HEAD、POST方法
- 通过
Content-Type头支持传输其他类型文档
- HTTP/1.1 RFC 1945发布之后的几个月发布了RFC 2068,想通过设计解决协议中的问题,后又被不断修订成多个部分
- 链接复用 Keep-Alive、缓存机制、内容协商
- Pipelining 机制,不用接收第一个请求的完整响应,就发送第二个请求
- 响应支持Chunked
- Host头,同一IP支持多个托管多个域名
- 新增PUT、DEELTE、OPTIONS、TRACE等方法
- HTTP/2 RFC 9113 1.1经过了很多年的发展
- 对原有1.1进行了压缩,性能更好,但是人读不懂
- multiplexed 多路复用,同一个链接通过二进制分帧 + 流可以交错发送多个请求
- 较HTTP 1.1 语义不变,只改传输机制
- HTTP/3 RFC 9114
- HTTP over QUIC,解决TCP层包的重传可能block所有数据流的问题,QUIC基于UDP传输多个流,自己实现了可靠传输,互不干扰
- 较HTTP 1.1 语义不变,只改传输机制
HTTP报文结构 #
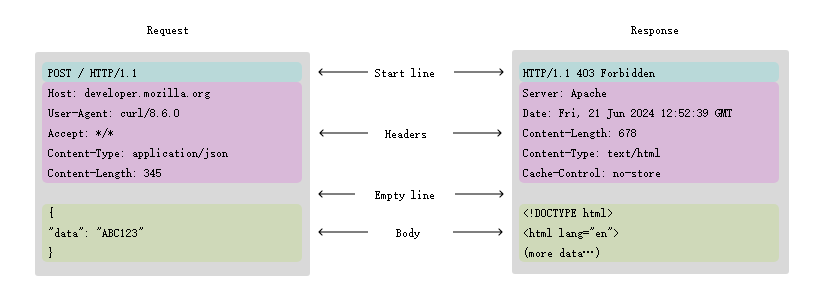
HTTP 消息的起始行和标头统称为请求的头部 Head,其后包含其内容的部分称为正文 Body
HTTP链接 #
Keep Alive #
HTTP 初始版本 和 1.0版本 默认使用 short-lived connection,即每个HTTP请求都会建立一个TCP链接,而建立TCP链接又是一个很耗时的操作。HTTP 1.1版本默认使用 persistent connection,或 keep-alive connection,即多次HTTP请求复用同一个TCP链接,通过Keep-Alive header 指定这个TCP链接 open多长时间,很多人口中说的HTTP长链接。
这样做也有缺陷,导致了 HOL(Head-of-line blocking) 问题的产生,后续的请求需要等待前一个请求的响应;同时就算没有HTTP请求,TCP链接也要保持open,更消耗资源
HTTP pipelining #
HTTP/1.1 引入的一种优化机制,允许客户端在不等待前一个响应的情况下,连续发送多个请求,默认浏览器没有启用该机制
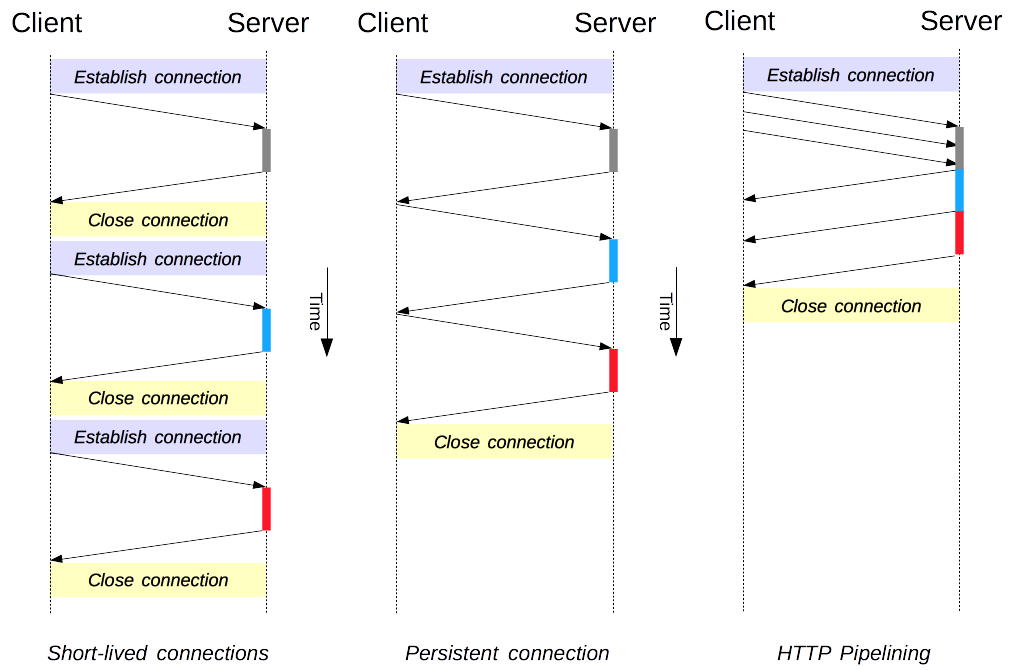
不幸的是,HTTP/1.1 要求响应必须按照接收请求的顺序返回,因此如果某个请求需要很长时间才能完成,仍然可能会发生 HOL 问题。
Head-of-line blocking #
分为 application-level 和 transport-layer HOL blocking
application-level HOL blocking 类似上面的HTTP 1.1 及pipelining中描述的问题,HTTP/2 通过 multiplexing 多路复用的方式解决了application-level的问题。
HTTP/2 在单个 TCP 连接上使用多个带编号的流,交错发送多个请求和响应,而流优先级则有助于服务器决定首先发送哪些流
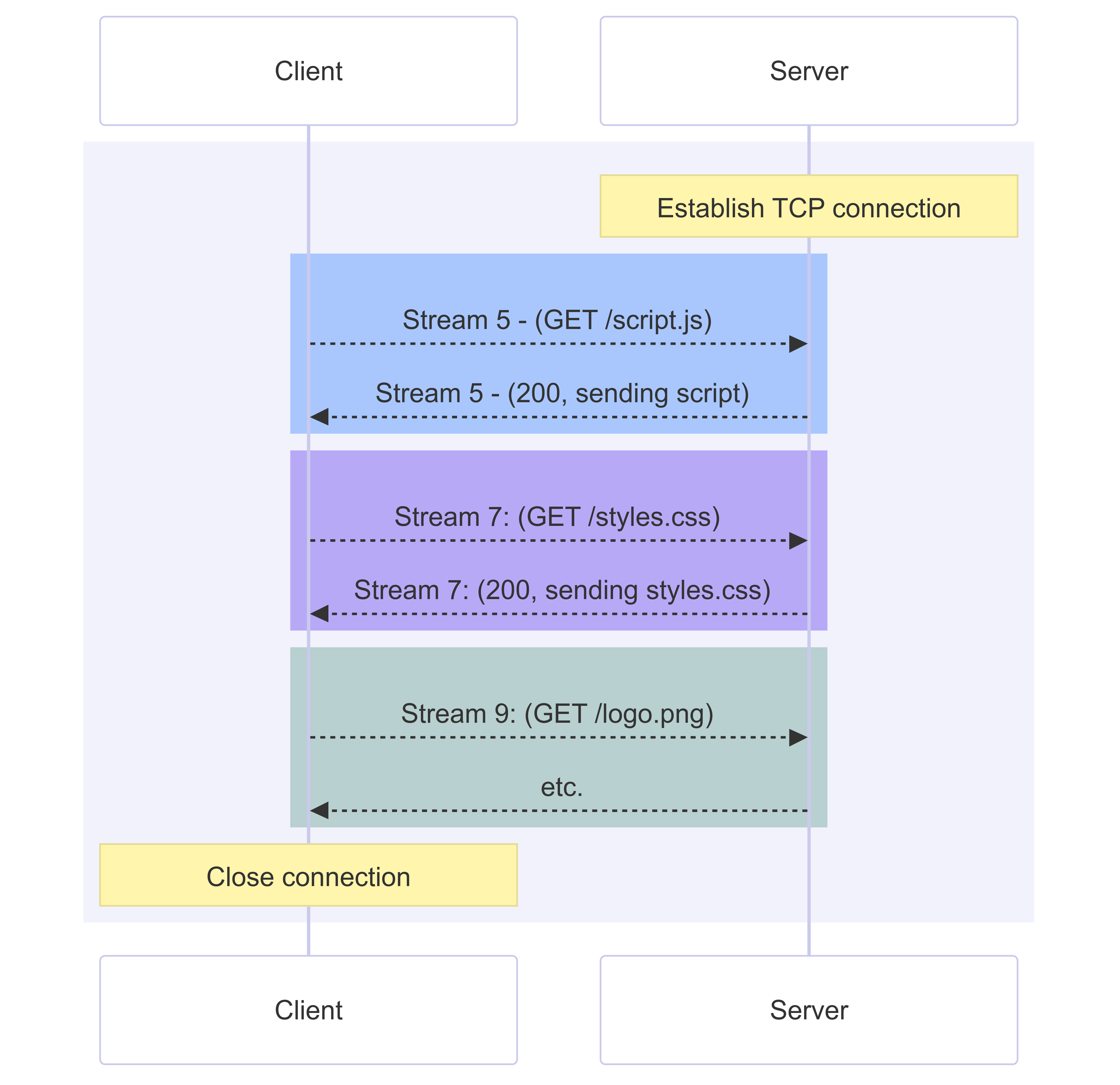
传输层的丢包仍然会导致 HOL blocking,HTTP/2 运行在 TCP 之上,丢失的 TCP segment 会使该连接上所有流 blocking,直到丢失的数据被重传
HTTP/3 通过使用 QUIC over UDP 解决了transport-layer HOL blocking的问题,多个独立的流互不干扰
Proxy #
分为正向代理forward proxies和反向代理reverse proxies,正向代理针对的目标是client,如向client通过代理访问互联网;反向代理针对的是内部服务,如隐藏内部服务身份。
我们可以通过 X-Forwarded-For 头获得访问代理前client的原始IP。
可以设置以下环境变量来让curl等命令通过代理访问,但为什么设置的都是 http://127.0.0.1:30081?
http_proxy=http://127.0.0.1:30081
https_proxy=http://127.0.0.1:30081
↑ ↑
这是"目标流量类型" 这是"与代理通信的协议"
首先这里的 http:// 指的是客户端到代理的协议,只是说明用HTTP 协议连接这个代理
当 curl 访问 https://example.com 时,会向代理发一个特殊的 HTTP 请求:
CONNECT example.com:443 HTTP/1.1
Host: example.com:443
HTTP/1.1 200 Connection Established
代理收到后链接就会进入透明模式,转发TCP流,这个叫做 HTTP CONNECT 隧道,代理并不感知内容,TLS 握手还是直接发生在 curl 和目标服务器之间
curl ──TCP_A── proxy ──TCP_B── example.com
read(TCP_A) → write(TCP_B)
read(TCP_B) → write(TCP_A)
回到HTTP,当 curl 访问 http://example.com 时,会向代理发包含绝对路径的 HTTP 请求
GET http://example.com/index.html HTTP/1.1
Host: example.com
代理解析这个请求,知道目标是 example.com,然后自己发起第二段请求,注意变为了相对路径
GET /index.html HTTP/1.1
Host: example.com
client ──HTTP── proxy ──HTTP── example.com
- HTTP 代理是7层代理,而SOCKS5 代理是4层代理
- HTTP 代理通常不需要客户端先解析目标域名,所以不受本地 DNS 污染影响
- SOCKS5 是否受影响,取决于客户端是“本地解析后再交给代理”,还是“把域名直接交给代理解析”
- 在 curl 里通常要用 socks5h:// 才表示“把域名直接交给代理解析”;socks5:// 往往是本地先解析
- 这个过程并不是本机先发一个 DNS 请求,然后这个 DNS 请求包再被 SOCKS5 代理转发出去;而是,SOCKS5具有类似HTTP CONNECT的二进制协议,curl 直接向 SOCKS5 代理发一个“CONNECT 请求”,请求里写的目标不是 IP,而是域名,代理拿到域名后,自己去解析,再代你连过去
Upgrade #
WebSocket 本质是和 HTTP 同一层级但完全不同的协议,可以实现浏览器和服务器的相互通信
通过 HTTP 协议 Upgrade 来完成 WebSocket 的建立,相当于复用已有的 TCP 连接,浏览器不用暴露低级别的TCP API,能复用现有的基础设施
GET /chat HTTP/1.1
Host: example.com
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Version: 13
HTTP/1.1 101 Switching Protocols
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
HTTP 升级完成后,传输的不再是 HTTP 报文,而是 WebSocket 帧,轻量的二进制帧,没有 HTTP 的 header 开销,每次通信不需要重复携带 Cookie、UA 等信息,这里不展开介绍。
Sec-WebSocket-Key 是用来确认服务器是支持 WebSocket 的,通过返回 Sec-WebSocket-Accept 来确认(客户端发送 WebSocket 握手请求,但服务器是一个普通 HTTP 服务器,不理解 WebSocket,服务器可能返回 200 OK,客户端误以为升级成功,开始发 WebSocket 帧导致错乱)
Sec-WebSocket-Accept =
base64(SHA1(key + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"))
↑
魔法字符串,写死在 RFC 6455 里
SSE #
SSE(Server-sent events) 是单向的服务器推送,基于普通 HTTP,不需要协议升级。
GET /events HTTP/1.1
Accept: text/event-stream ← 关键 header
HTTP/1.1 200 OK
Content-Type: text/event-stream ← 关键
Cache-Control: no-cache
Connection: keep-alive
← 连接不关闭,持续发数据
之后服务器保持连接不断,不断往里写数据。ChatGPT/Calude 对话的流式输出用的就是SSE。
HTTP请求方法 #
常用方法:
- GET — 获取资源,只读,不修改服务器数据,参数在 URL 中
- POST — 提交数据,创建资源(如提交表单、上传文件)
- PUT — 替换资源,将目标资源整体更新为请求体内容
- DELETE — 删除指定资源
- PATCH — 部分更新资源(只修改指定字段,与 PUT 整体替换不同)
其他方法:
- HEAD — 与 GET 相同,但只返回响应头,不返回响应体,常用于检查资源是否存在或获取元信息
- OPTIONS — 查询服务器支持哪些方法,CORS 预检请求会用到
- CONNECT — 建立隧道连接,主要用于 HTTPS 代理
- TRACE — 回显服务器收到的请求,用于调试,判断中间链路是否修改了请求(生产环境通常禁用)
TRACE / HTTP/1.1
Host: example.com
User-Agent: curl/7.88.1
Cookie: session=abc123
HTTP/1.1 200 OK
Content-Type: message/http ← 注意这个 Content-Type
TRACE / HTTP/1.1 ← 响应体就是你发的请求原文
Host: example.com
User-Agent: curl/7.88.1
Cookie: session=abc123
| 方法 | 幂等性 | 只读 | 请求体 | 典型用途 |
|---|---|---|---|---|
| GET | ✅ | ✅ | 无 | 查询资源 |
| POST | ❌ | ❌ | 有 | 创建资源 |
| PUT | ✅ | ❌ | 有 | 整体替换 |
| PATCH | ❌ | ❌ | 有 | 部分更新 |
| DELETE | ✅ | ❌ | 可有可无 | 删除资源 |
| HEAD | ✅ | ✅ | 无 | 获取响应头 |
| OPTIONS | ✅ | ✅ | 无 | 查询支持的方法 |
幂等:多次执行结果相同,如 PUT 替换整体是幂等的
协议层面并没有禁止 GET 携带请求体,但是在现实中不建议,也有很多限制,比如浏览器中GET请求不可以请求体,报错或忽略,GET URL长度有限制,浏览器层面的限制
POST较GET更安全?从抓包上来看都是明文没有区别,但是GET数据是在URL中,可能因为浏览记录导致信息泄露等,同时如果GET用于修改数据可能会因为一些其他机制引起安全问题
HTTP状态码 #
状态码分五大类,首位数字代表类别。
Informational 1xx
| 状态码 | 含义 |
|---|---|
| 100 Continue | 服务器收到请求头,客户端可以继续发请求体 |
| 101 Switching Protocols | 协议升级,如切换到 WebSocket |
Successful 2xx
| 状态码 | 含义 |
|---|---|
| 200 OK | 请求成功 |
| 201 Created | 资源创建成功(常见于 POST) |
| 204 No Content | 成功但无响应体(常见于 DELETE) |
| 206 Partial Content | 分片下载,返回部分内容 |
Redirection 3xx
| 状态码 | 含义 |
|---|---|
| 301 Moved Permanently | 永久重定向,浏览器会缓存新地址 |
| 302 Found / Moved Temporarily | 临时重定向,不缓存 |
| 304 Not Modified | 资源未变化,用缓存即可 |
Client Error 4xx
| 状态码 | 含义 |
|---|---|
| 400 Bad Request | 请求格式错误 |
| 401 Unauthorized | 未认证(没登录) |
| 403 Forbidden | 已认证但无权限 |
| 404 Not Found | 资源不存在 |
| 405 Method Not Allowed | 该资源不支持此请求方法 |
| 409 Conflict | 资源冲突(如重复创建) |
| 410 Gone | 资源已永久删除 |
Server Error 5xx
| 状态码 | 含义 |
|---|---|
| 500 Internal Server Error | 服务器内部错误 |
| 502 Bad Gateway | 网关从上游服务器收到无效响应 |
| 503 Service Unavailable | 服务暂时不可用(过载或维护) |
| 504 Gateway Timeout | 网关等待上游响应超时 |
几个容易混淆的点
401 Unauthorized vs 403 Forbidden
- 401 是"你是谁我不知道",需要登录
- 403 是"我知道你是谁,但你没权限"
301 Moved Permanently vs 302 Moved Temporarily
- 301 浏览器会记住新地址,下次直接去新地址,SEO 权重也会转移
- 302 每次还是先问服务器,适合临时跳转,比如服务暂时异常导航到统一的提示页
502 Bad Gateway vs 504 Gateway Timeout
- 502 是上游返回了"坏的"响应
- 504 是上游根本没响应,超时了
MIME #
媒体类型(以前称为Multipurpose Internet Mail Extensions)标识文档、文件或字节集合的性质和格式。
MIME结构
type/subtype;parameter=value
application/octet-stream: 未知二进制文件,如果Content-Disposition为attachment,则建议弹出“另存为”对话框text/plain: 未知文本文档,类似text/css/text/html/text/javascriptapplication/json: jsonmultipart/form-data: Form表单,multipart是指包含多个部分,每个部分用--xxxxxxx边界分隔,每个部分可以有独立的header,常见的Content-Disposition指定字段名/文件名,Content-Type数据类型Content-Type: multipart/form-data; boundary=boundaryString (other headers associated with the multipart document as a whole) --boundaryString Content-Disposition: form-data; name="myFile"; filename="img.jpg" Content-Type: image/jpeg (data) --boundaryString Content-Disposition: form-data; name="myField" (data) --boundaryString (more subparts) --boundaryString--multipart/byteranges: 和multipart/form-data是反方向的,不是请求包含了多份数据,是响应的文件被分成了多分,用于下载时断点续传、视频播放跳播等GET /video.mp4 HTTP/1.1 Range: bytes=0-999, 5000-5999, 9000-9999HTTP/1.1 206 Partial Content Content-Type: multipart/byteranges; boundary=boundaryString --boundaryString Content-Type: video/mp4 Content-Range: bytes 0-999/10000 <第0-999字节的数据> --boundaryString Content-Type: video/mp4 Content-Range: bytes 5000-5999/10000 <第5000-5999字节的数据> --boundaryString Content-Type: video/mp4 Content-Range: bytes 9000-9999/10000 <第9000-9999字节的数据> --boundaryString--
Content-Type: multipart/byteranges和Transfer-Encoding: chunked的对比
multipart/byteranges是含义上可能包含了多份数据,参看以上
Transfer-Encoding: chunked用于不知道要返回多大的数据,一直返回数据,单个资源流式传输HTTP/1.1 200 OK Transfer-Encoding: chunked 7\r\n ← 这个 chunk 有 7 个字节(16进制) Hello, \r\n ← 数据 6\r\n World!\r\n 0\r\n ← 0 表示结束 \r\n2者可以结合使用,
chunked层级要高一点相当于对body数据进行了编码
内容协商 #
一种允许客户端和服务器端就交换的数据格式达成一致的机制
server-driven
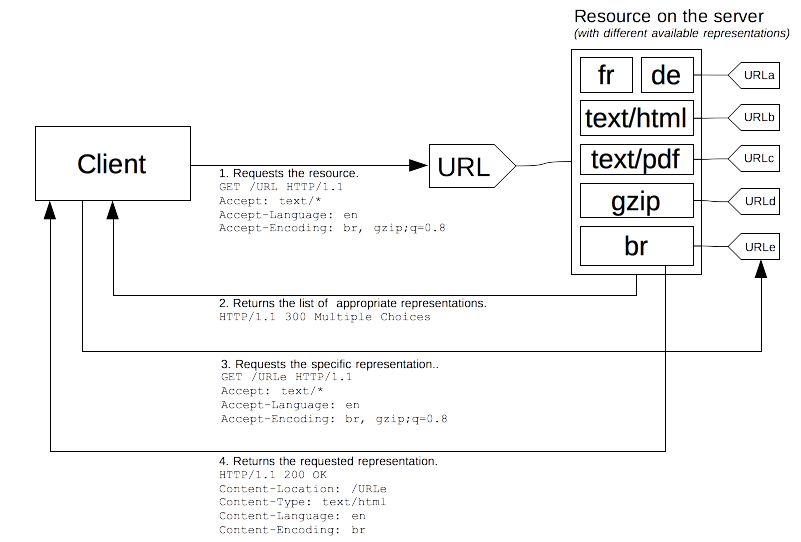
client-driven
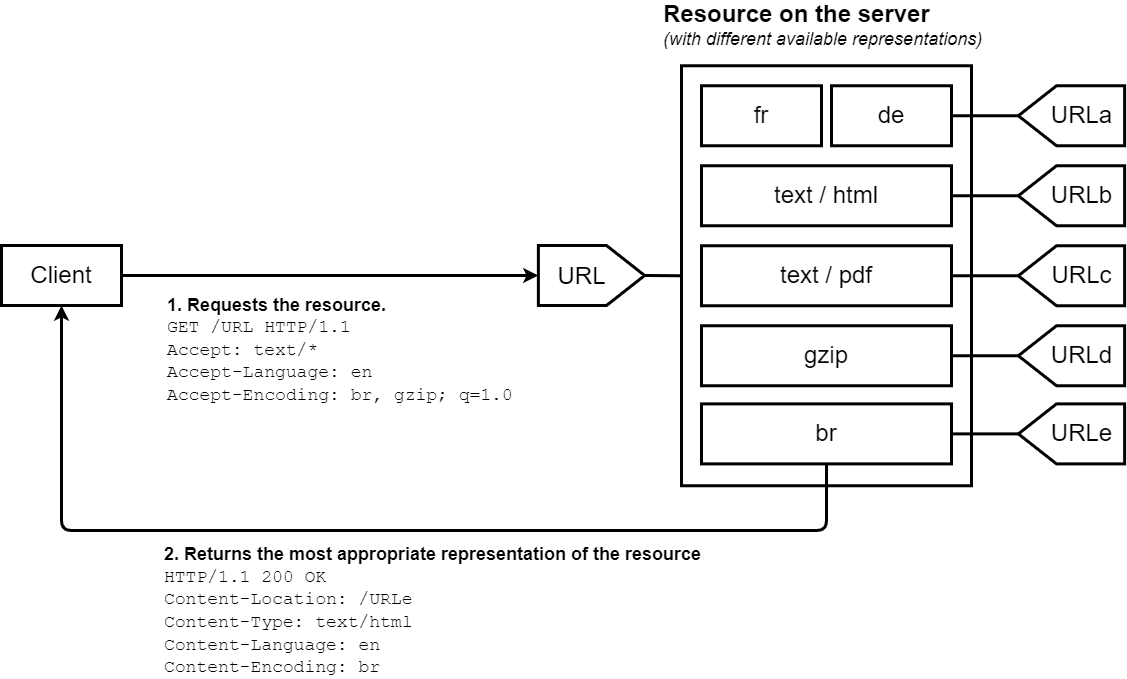
GET /data HTTP/1.1
Accept: application/json, text/xml;q=0.8
HTTP/1.1 200 OK
Content-Type: application/json
Vary: Accept
{"key": "value"}
Vary Header 会告知缓存哪些请求头影响了响应格式,缓存基于这些头部的不同,缓存不同的数据
Vary: Accept, Accept-Languageq 是
quality factor,表示客户端对某种格式的偏好程度,取值范围是 0 到 1。Accept: text/html, application/json;q=0.9, */*;q=0.5
text/html→ q=1.0(最优先,省略了)application/json→ q=0.9(次之)*/*→ q=0.5(任何格式都行,但优先级最低)
HTTP cookies #
HTTP is stateless, but not sessionless
HTTP 协议本身不保存任何请求之间的状态。每个请求对服务器来说都是全新的、独立的,服务器不记得你上一次请求是什么。 通过 HTTP cookies 允许使用有状态的 session,从而允许在每个 HTTP 请求上创建会话,以便共享相同的上下文或状态
请求1: POST /login
响应1: Set-Cookie: session_id=abc123
请求2: GET /profile
Cookie: session_id=abc123 ← 客户端主动带上
服务器查询 abc123 对应的数据,就能认出你,但这个"认出"不是 HTTP 协议做的,是应用代码 + 数据库/缓存做的。
Cookie 通过两个属性控制发送(自动携带)范围:Domain 和 Path。
Set-Cookie: token=abc; Domain=example.com; Path=/api
只有访问 example.com(及子域名)下的 /api/* 路径时才会自动携带上这个 Cookie。(如果不设置 Domain,默认只发给当前域名,不包括子域名,反而限制更高)
同时,Domain 也决定 JS 通过 document.cookie 是否可见
通过 SameSite 控制跨站发送
Set-Cookie: token=abc; SameSite=Strict
| 值 | 行为 |
|---|---|
Strict | 只有同站请求才发送,跨站完全不发 |
Lax | 跨站的 GET 请求会发,其他跨站请求不发(默认值) |
None | 任何情况都发送,但必须同时设置 Secure |
同站(Same-Site)的判断标准: 看的是 eTLD+1(有效顶级域名 + 一级)是否相同,不管端口和子域名
https://sub.example.com/path ↑ eTLD+1 = example.com (eTLD 是 .com,再加一级就是 example.com)
SameSite 主要是为了防御 CSRF 攻击。
跨域问题 #
Same-Origin Policy 的要求如下,协议、域名、端口三者必须完全相同才算同源:
| 组成部分 | 说明 |
|---|---|
| 协议 | http vs https → 不同源 |
| 域名 | example.com vs sub.example.com → 不同源 |
| 端口 | :80 vs :8080 → 不同源 |
SOP 并不是禁止所有跨域,主要限制的是用 JS 读取跨域资源(能发出去,响应也回来了,只是浏览器不让读):
允许的跨域操作:
<img src>加载图片<script src>加载脚本<link href>加载 CSS<form>提交(但读不到响应)- 页面跳转、重定向
禁止的跨域操作:
fetch/XMLHttpRequest读取响应- 读取跨域 iframe 的 DOM
- 读取跨域 Cookie、Storage
核心目标是防止恶意网站读取你在其他网站的数据。SOP 保护的是读,CSRF 攻击的是写,两者针对的方向不同,所以 SOP 防不住 CSRF。
CORS(Cross-Origin Resource Sharing),是一套让服务器主动声明哪些跨域请求被允许的机制。本质上是对 SOP 的受控进行调整,默认跨域不能读,但服务器可以通过响应头告诉浏览器"这个来源我信任,可以让它读"。
满足以下条件时直接发,不预检:
- 方法是
GET/POST/HEAD Content-Type限于text/plain、multipart/form-data、application/x-www-form-urlencoded
请求:
GET /api HTTP/1.1
Origin: https://a.com ← 浏览器自动加
响应:
Access-Control-Allow-Origin: https://a.com ← 服务器表示允许
浏览器检查这个响应头,有且匹配,JS 能读响应。
不满足预检条件时,浏览器先发 OPTIONS 请求(尽可能避免 DELETE、PUT 会修改服务器数据,如果直接发出去再发现不被允许,但操作已经执行了):
# 第一步:预检
OPTIONS /api HTTP/1.1
Origin: https://a.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: Content-Type
# 我真正的请求会带上 Content-Type Header,看是否可以
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: https://a.com # 对应请求 Origin
Access-Control-Allow-Methods: GET, POST, DELETE
Access-Control-Allow-Headers: Content-Type
Access-Control-Max-Age: 86400
# 预检结果缓存多久(秒),缓存期内不再预检
# 第二步:服务器允许后,才发真正的请求
# 响应缺少对应的 Allow 头,浏览器会认为预检失败,真正的请求不会发出
POST /api HTTP/1.1
Origin: https://a.com
Content-Type: application/json
{"name": "hello"}
缓存 #
强缓存,浏览器直接用本地缓存,不发请求
响应头:
Cache-Control: max-age=3600 ← 缓存 3600 秒
Expires: Wed, 21 Mar 2025 08:00:00 GMT ← 过期时间(老方式)
有效期内再次请求同一资源,浏览器直接从缓存读,状态码显示 200 (from cache),完全不经过网络。Cache-Control 优先级高于 Expires。
协商缓存,浏览器带上缓存标识去问服务器:我这个版本还有效吗?
# 第一次响应
Last-Modified: Tue, 20 Mar 2025 10:00:00 GMT
# 再次请求
If-Modified-Since: Tue, 20 Mar 2025 10:00:00 GMT
# 服务器判断没变化
HTTP/1.1 304 Not Modified ← 不返回 body,浏览器用缓存
# 第一次响应
ETag: "abc123"
# 再次请求
If-None-Match: "abc123"
# 服务器判断没变化
HTTP/1.1 304 Not Modified
ETag 优先级高于 Last-Modified,因为更精确(时间精度有限,ETag 可以基于内容的哈希)。
如果文件名固定 app.js 设置了强缓存 max-age=31536000(一年),用户浏览器就会一直用本地缓存,即使你部署了新版本,用户也看不到更新。
可以根据文件内容生成 hash,加入文件名
app.abc123.js
app.def456.js ← 内容变了,hash 变了,文件名也变了
同时index.html 不能缓存,index.html 必须每次都拿最新的,才能引用到最新的 JS/CSS。
<script src="/app.def456.js"></script>
旧的 app.abc123.js 还在浏览器缓存里,等自然淘汰就行。